PSTAT 100: Lecture 17
Classification
RMS Titanic
- The RMS Titanic was an ocean liner that set sail from Southampton (UK) to New York (US) on April 10, 1912.
- 5 days into its journey, on April 15, 1912, the ship collided with an iceberg and sank.
- Tragically, the number of lifeboats was far fewer than the total number of passengers, and as a result not everyone survived.
- A passenger/crew manifest still exists, which includes survival statuses.
RMS Titanic
First Model
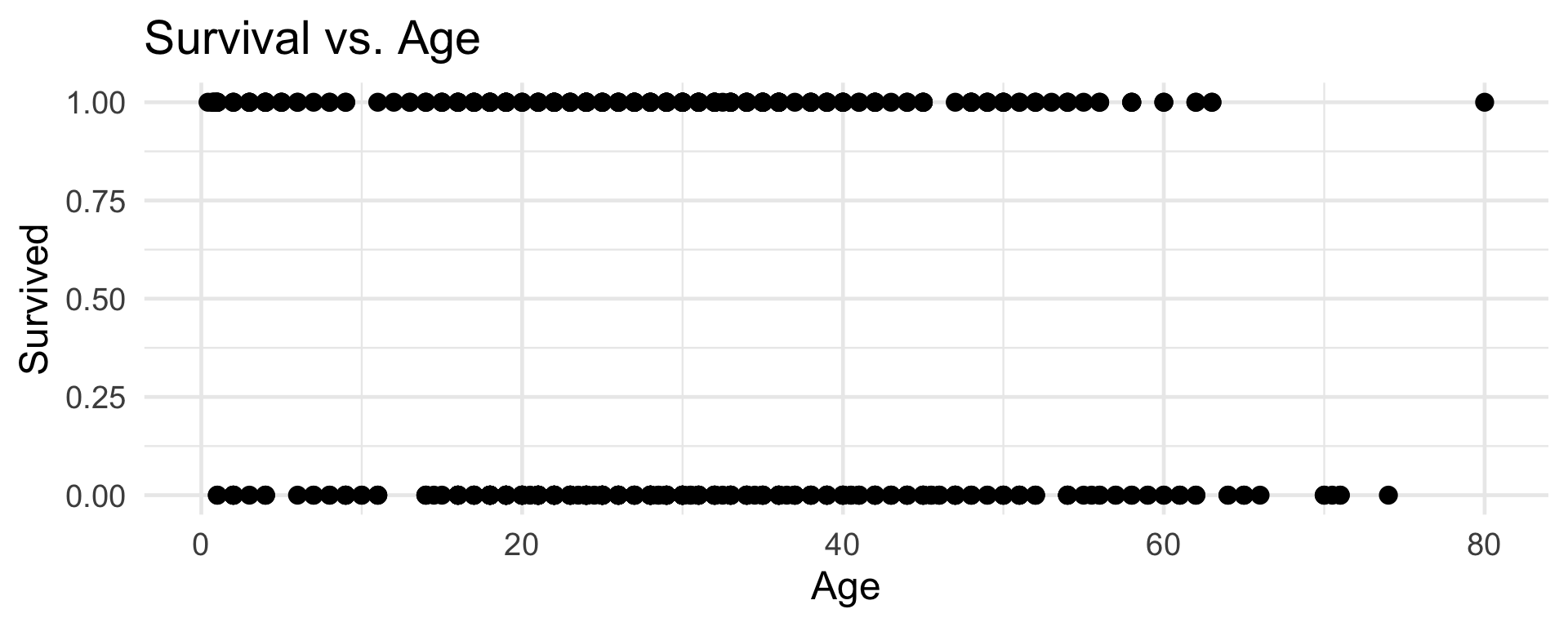
We just have to be a bit more creative about our model proposition.
Let’s see what happens if we try to fit a “linear” model:
yi= β0 + β1xi+ εi
RMS Titanic
First Model
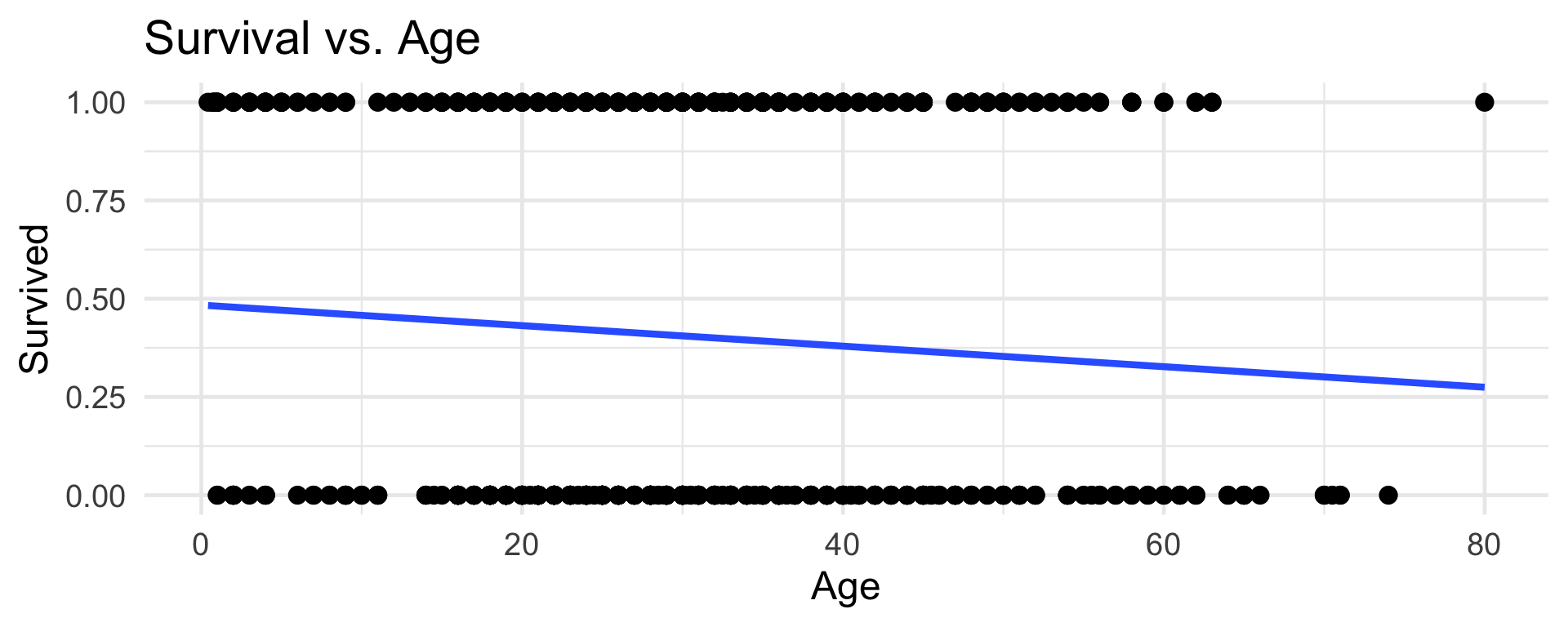
- But what does this line mean?
- The problem is in our proposed model.
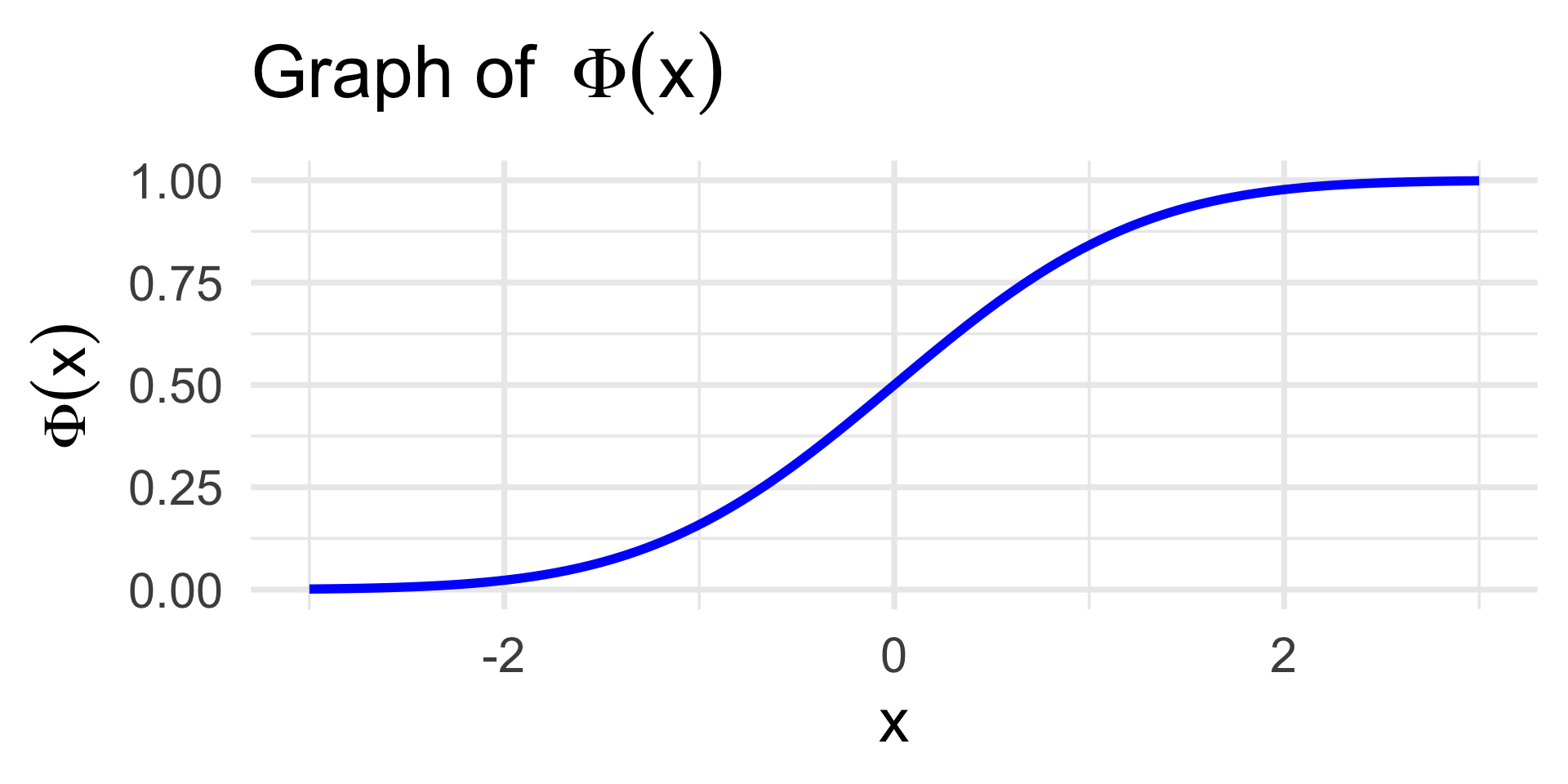
Probit vs. Logit Models
Probit Model: πi = Φ(β0 + β1 xi)
\[ \Phi(x) := \int_{-\infty}^{x} \frac{1}{\sqrt{2\pi}} e^{-z^2 / 2} \ \mathrm{d}z \]
Logit Model: πi = Λ(β0 + β1 xi)
\[ \Lambda(x) := \frac{1}{1 + e^{-x}} \]
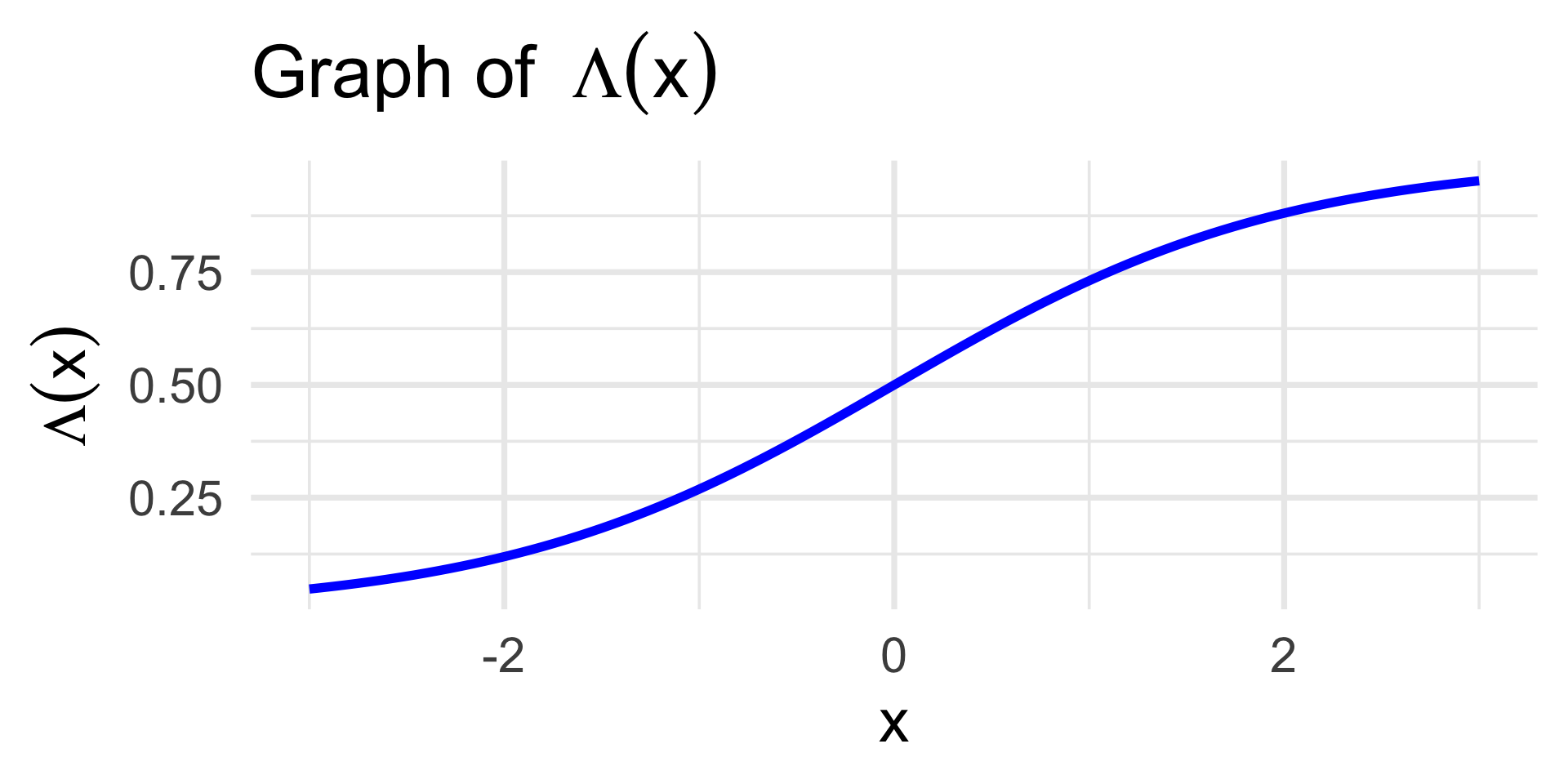
- Logit models are more commonly referred to as logistic regression models.
Logistic Regression
Titatnic Dataset
Code
glm1_c <- glm(Survived ~ Fare, data = titanic, family = "binomial") %>% coef()
pred_surv <- Vectorize(function(x){
1 / (1 + exp(-glm1_c[1] - glm1_c[2] * x))
})
titanic %>% ggplot(aes(x = Fare, y = Survived)) +
geom_point(size = 3) +
theme_minimal(base_size = 18) +
geom_smooth(method = "lm", formula = y ~ x, se = FALSE,
aes(colour = "Linear Regression"), linewidth = 2) +
stat_function(fun = pred_surv,
aes(colour = "Logistic Regression"), linewidth = 2) +
labs(colour = "Survival Probability") +
ggtitle("Survival Status vs. Fare")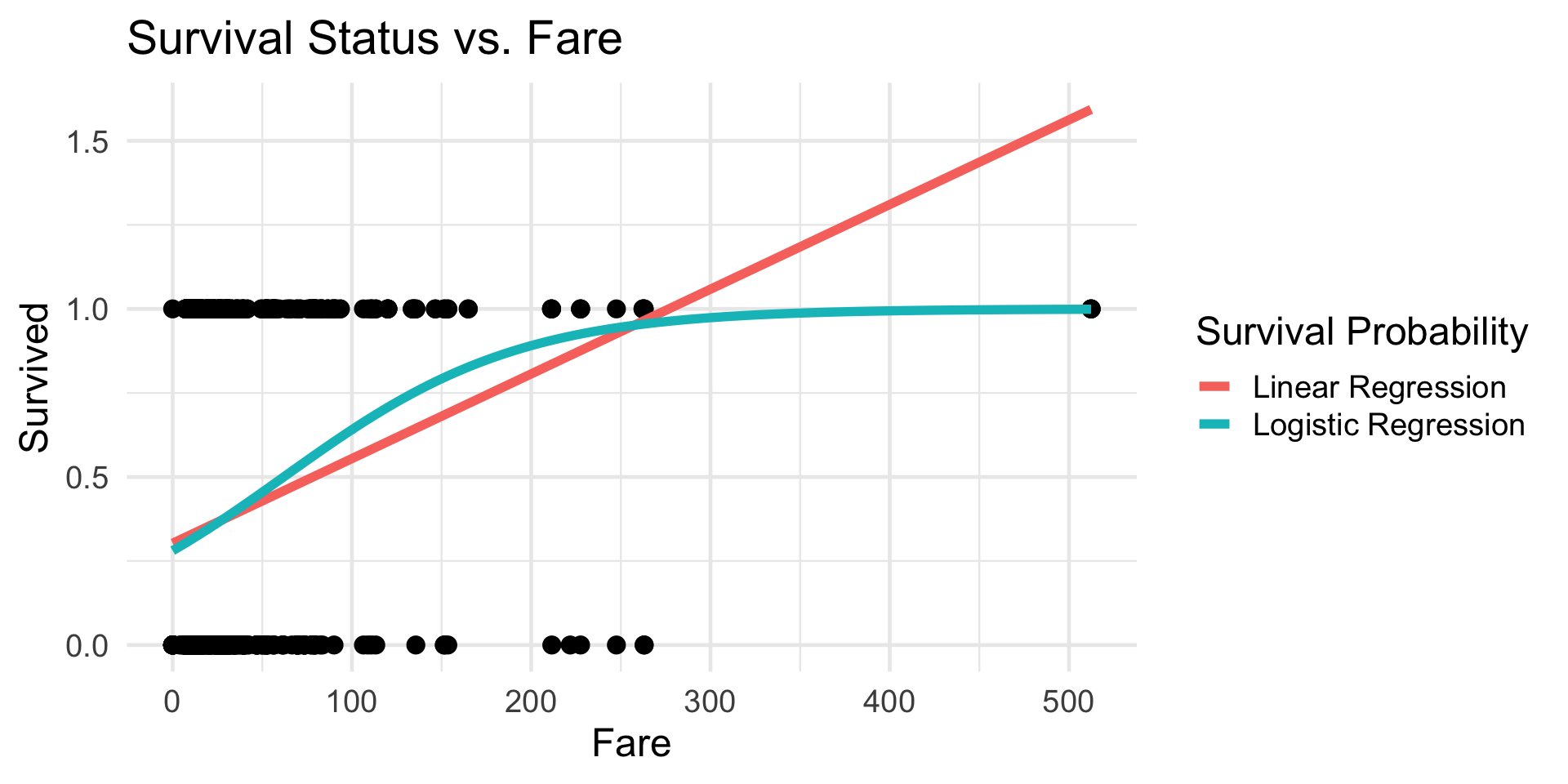
- Does this make sense, based on our background knowledge?
Confusion Matrices

Performance of a Classifier
ROC Curves
Allow me to elaborate a bit more on this last point.
The vertical axis of a ROC curve effectively represents the probability of a good thing; ideally, we’d like a classifier that has a 100% TPR!
Simultaneously, an ideal classifier would also have a 0% FPR (which is precisely what is plotted on the horizontal axis of an ROC curve).

Performance of a Classifier
ROC Curves
- ROC curves can also be used to compare across models as well.
- Model 1: Using
Fare,Age,Sex, andCabinas predictors - Model 2: Using
FareandAgeas predictors
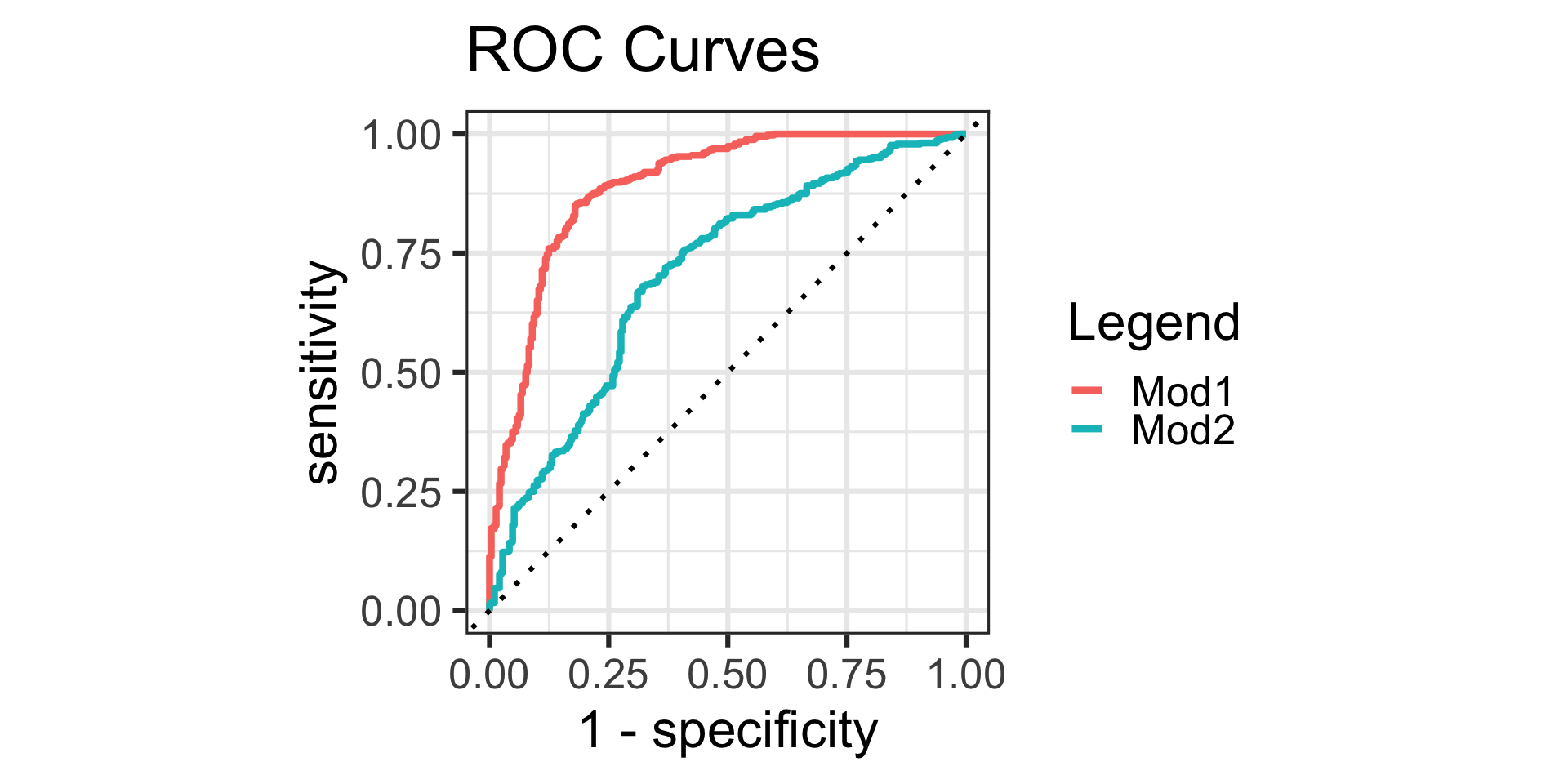
- The ROC curve for model 1 is farther from the diagonal than model 2, indicating that it is the better choice.
