PSTAT 100: Lecture 16
Regression, Part III
Mario Kart
- Let’s consider a dataset pertaining to Mario Kart.
- Specifically, this dataset tracks the selling price of used and new copies of Mario Kart for the Nintendo Wii.
| sell_price | cond |
|---|---|
| 47.55 | new |
| 33.05 | used |
| 42 | new |
| 44 | new |
| 71 | new |
| 41 | new |
| 37.02 | used |
Mario Kart
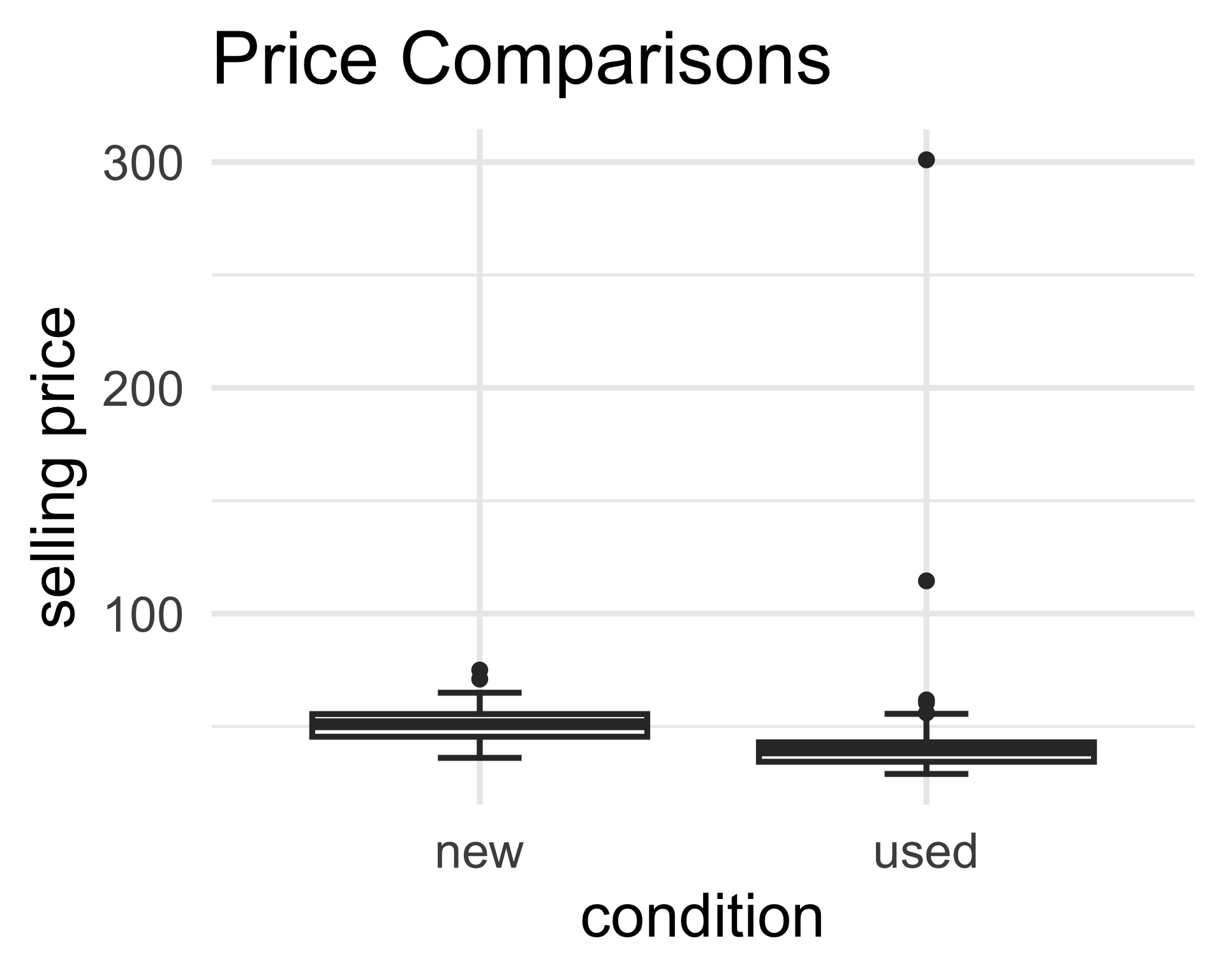
- Let’s remove the two unusually-expensive used copies from our consideration.
- Very likely, these were rare/antique copies which is why they sold for unusually high prices
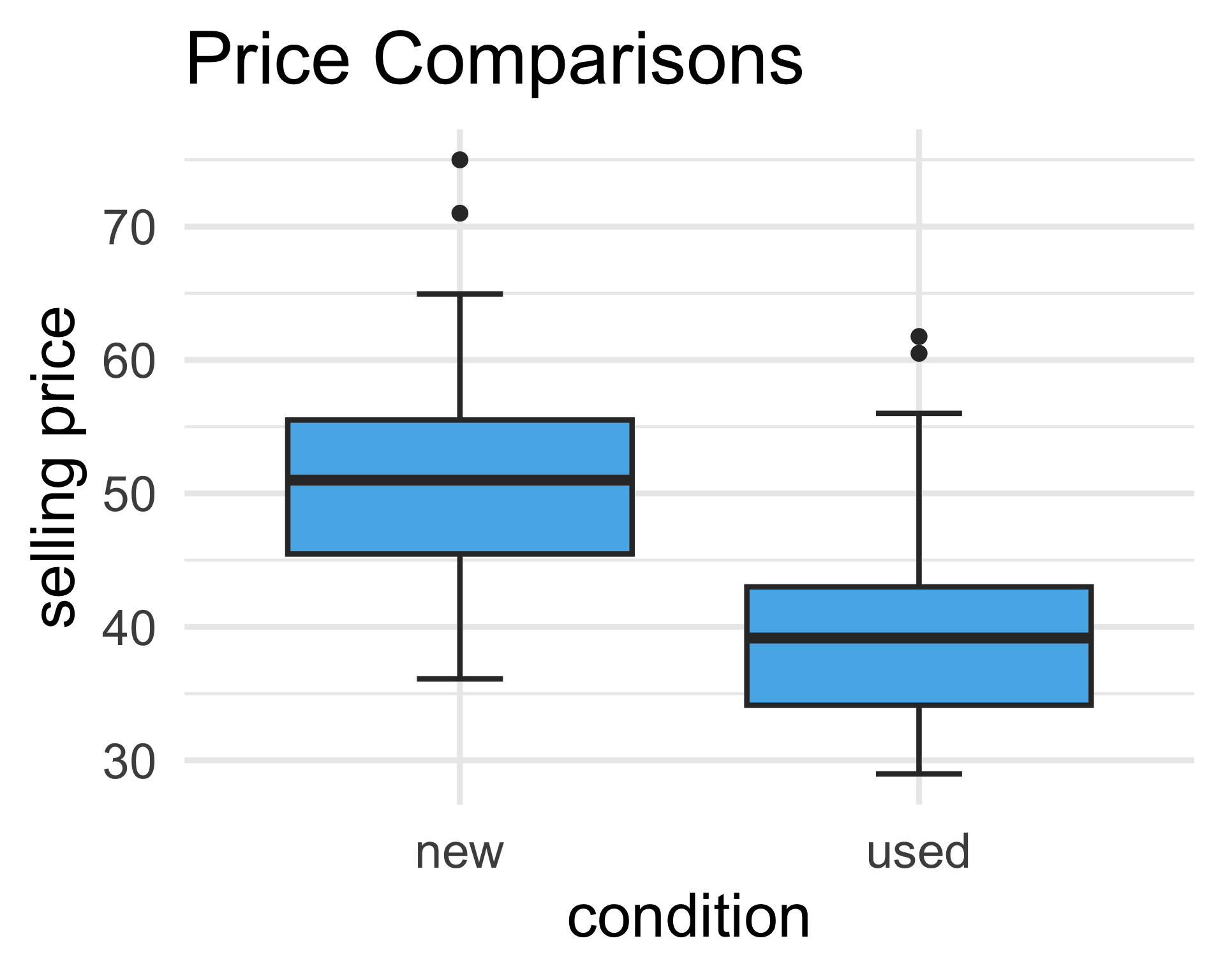
From our plot, it appears as though, on average, used copies sold for less than new copies.
But how might we model this statistically?
yi = β0 + β1 xi + εi?
Mario Kart
| sell_price | cond |
|---|---|
| 47.55 | new |
| 33.05 | used |
| 42 | new |

By the way, recall that a “scatterplot” is NOT a good plot for this particular dataset - I’m mainly including one to keep things consistent with out treatment of regression from the past few lectures.
47.55 = β0 + β1 (
new) + εi? That doesn’t seem right…The main idea is that our covariate is now categorical (as opposed to numerical). So, we need a new way to encode its observations into our model.
Idea: use indicators!
Mario Kart
| sell_price | cond |
|---|---|
| 47.55 | new |
| 33.05 | used |
| 42 | new |

\[ y_i = \beta_0 + \beta_1 \cdot 1 \! \! 1 \{ \texttt{condition}_i = \texttt{used} \} + \varepsilon_i \]
Mario Kart
| sell_price | cond |
|---|---|
| 47.55 | new |
| 33.05 | used |
| 42 | new |

\[ y_i = \begin{cases} \beta_0 + \beta_1 + \varepsilon_i & \text{if $i^\text{th}$ copy is used} \\ \beta_0 + \varepsilon_i & \text{if $i^\text{th}$ copy is new} \\ \end{cases} \]
- β0 can be interpreted as the average price among new copies
- β0 + β1 can be interpreted as the average price among used copies
- Hence, β1 can be interpreted as the average difference in price between new and used copies of the game
Mario Kart
\[ \widehat{y}_i = \beta_0 + \beta_1 1 \! \! 1\{\texttt{condition}_i = \texttt{used}\} \]
| cond | avg_price |
|---|---|
| new | 51.01 |
| used | 39.74 |
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 51.008 0.995 51.266 < 2e-16 ***
condused -11.271 1.305 -8.639 1.2e-14 ***
- Note: 39.74 - 51.0 = -11.26.
Encoding Categorical Variables
Multiple Levels
What if we have a covariate with more than two levels?
As an example, let’s return to the
palmerpenguinsdataset- Recall that this particular dataset tracks various characteristics of penguins from the Palmer Research Station in Antarctica
- One variable records the species of each penguin, as either Adélie, Chinstrap, or Gentoo
- As such,
speciesis a categorical variable that has three levels.
- As such,

Encoding Categorical Variables
Palmerpenguins species
| body_mass_g | species |
|---|---|
| 3750 | Adelie |
| 3800 | Adelie |
| 3250 | Adelie |
| NA | Adelie |
| 3450 | Adelie |
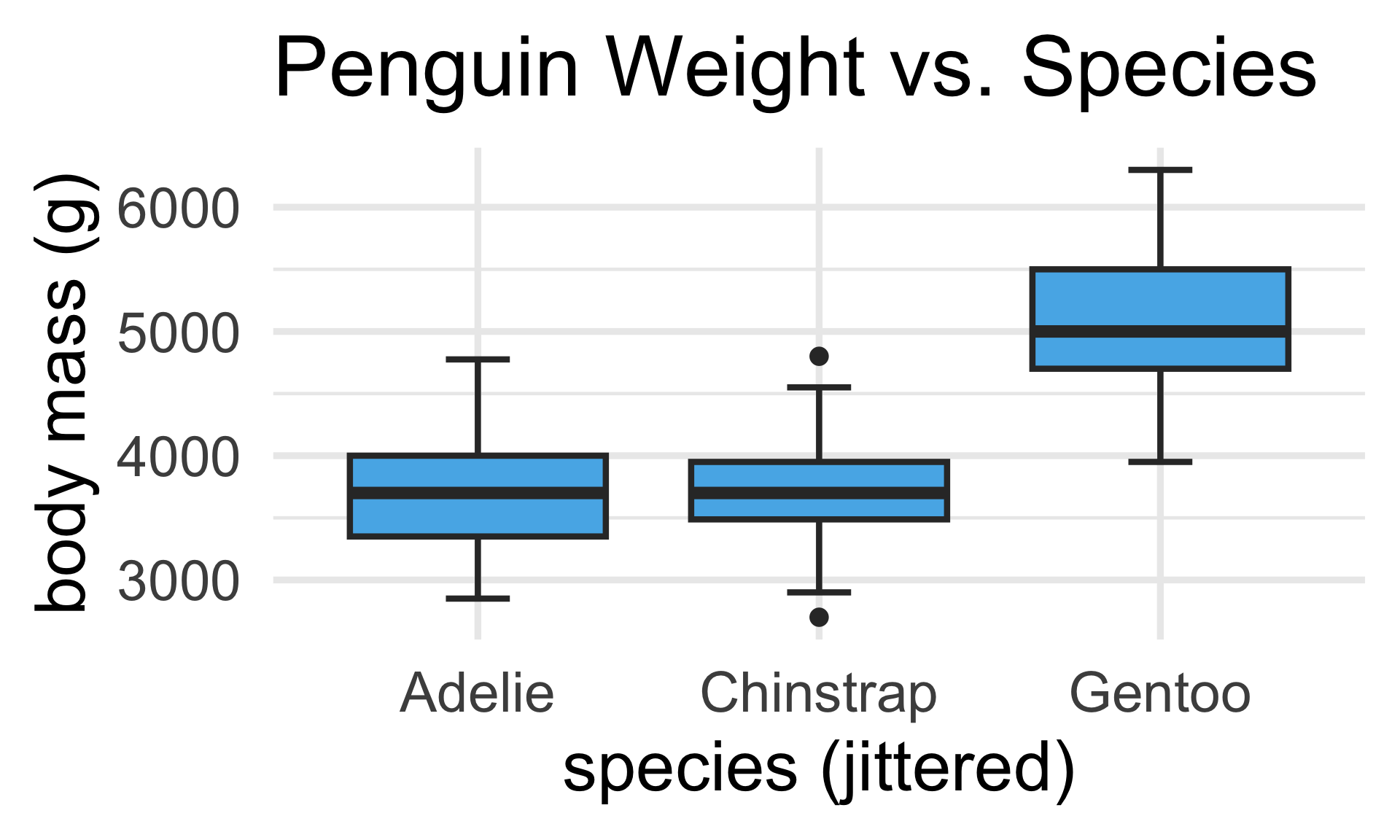
\[\begin{align*} y_i & = \beta_0 + \beta_1 1 \! \! 1 \{\texttt{species}_i = \texttt{Adelie}\} + \beta_2 1 \! \! 1 \{\texttt{species}_i = \texttt{Chinstrap}\} \\ & \hspace{15mm} + \beta_3 1 \! \! 1 \{\texttt{species}_i = \texttt{Gentoo}\} + \varepsilon_i \end{align*}\]
- What’s the intercept β0 doing here? (Hint: how many species are there?)
An Interesting Connection…
| sell_price | cond |
|---|---|
| 47.55 | new |
| 33.05 | used |
| 42 | new |
| 44 | new |
| 71 | new |
\[ y_i = \beta_0 + \beta_1 \cdot 1 \! \! 1 \{ \texttt{condition}_i = \texttt{used} \} + \varepsilon_i \]
An Interesting Connection…
| sell_price | cond |
|---|---|
| 47.55 | new |
| 33.05 | used |
| 42 | new |
| 44 | new |
| 71 | new |
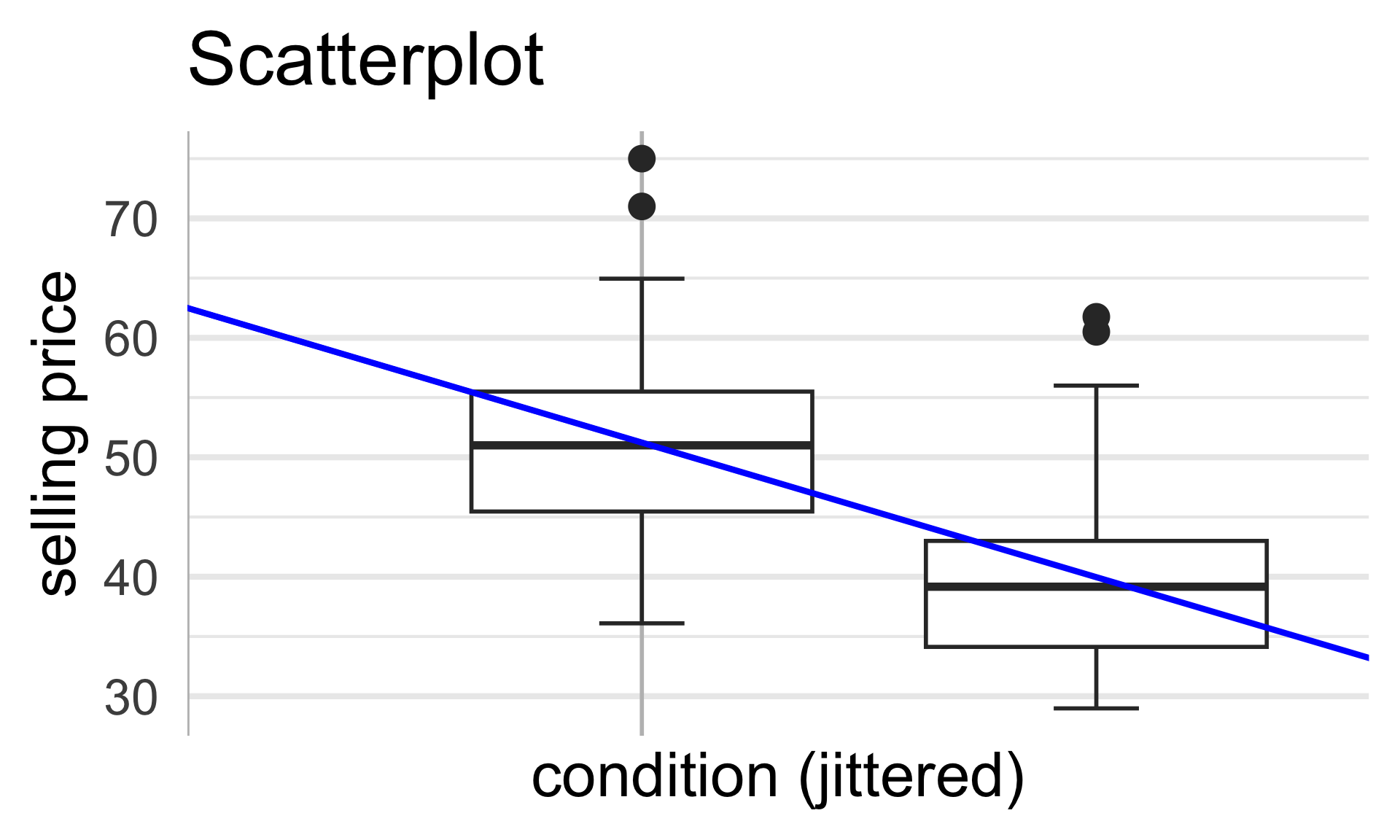
\[ y_i = \beta_0 + \beta_1 \cdot 1 \! \! 1 \{ \texttt{condition}_i = \texttt{used} \} + \varepsilon_i \]
An Interesting Connection…
| sell_price | cond |
|---|---|
| 47.55 | new |
| 33.05 | used |
| 42 | new |
| 44 | new |
| 71 | new |
y = (grand mean) + (deviations from grand mean) + (noise)
This is just ANOVA!
\[ y_{ij} = \mu + \tau_j + \varepsilon_{ij}; \quad i = 1, \cdots, n_j; \ j = 1, 2 \]
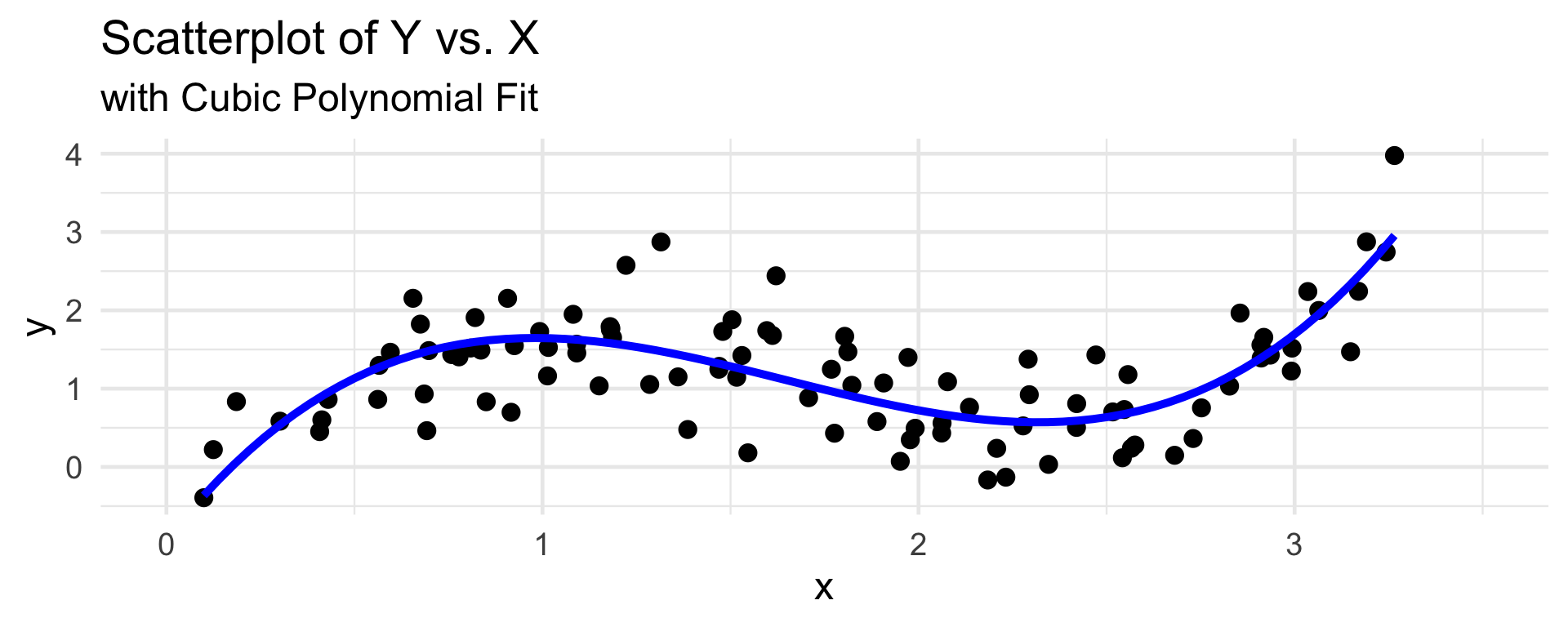
Polynomial Regression
- For example, polynomial regression essentially takes \(\phi_k(x) = x^k\)
- Aside: “raw” polynomials (x, x2, etc.) are not orthogonal, so technically we use an orthogonalized version of polynomials (e.g. Legendre polynomials or Hermite polynomials).
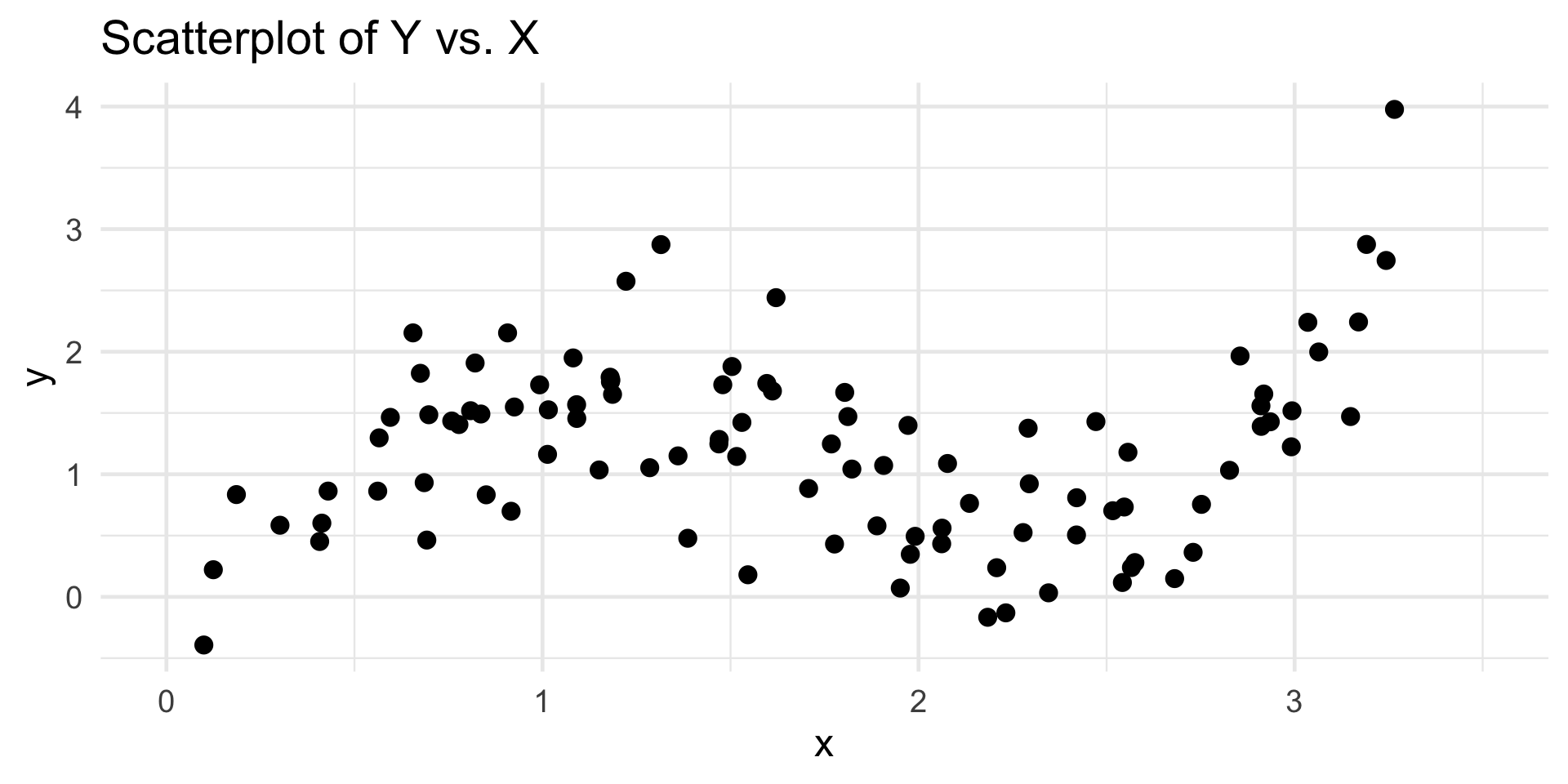
Piecewise Regression
Example Data
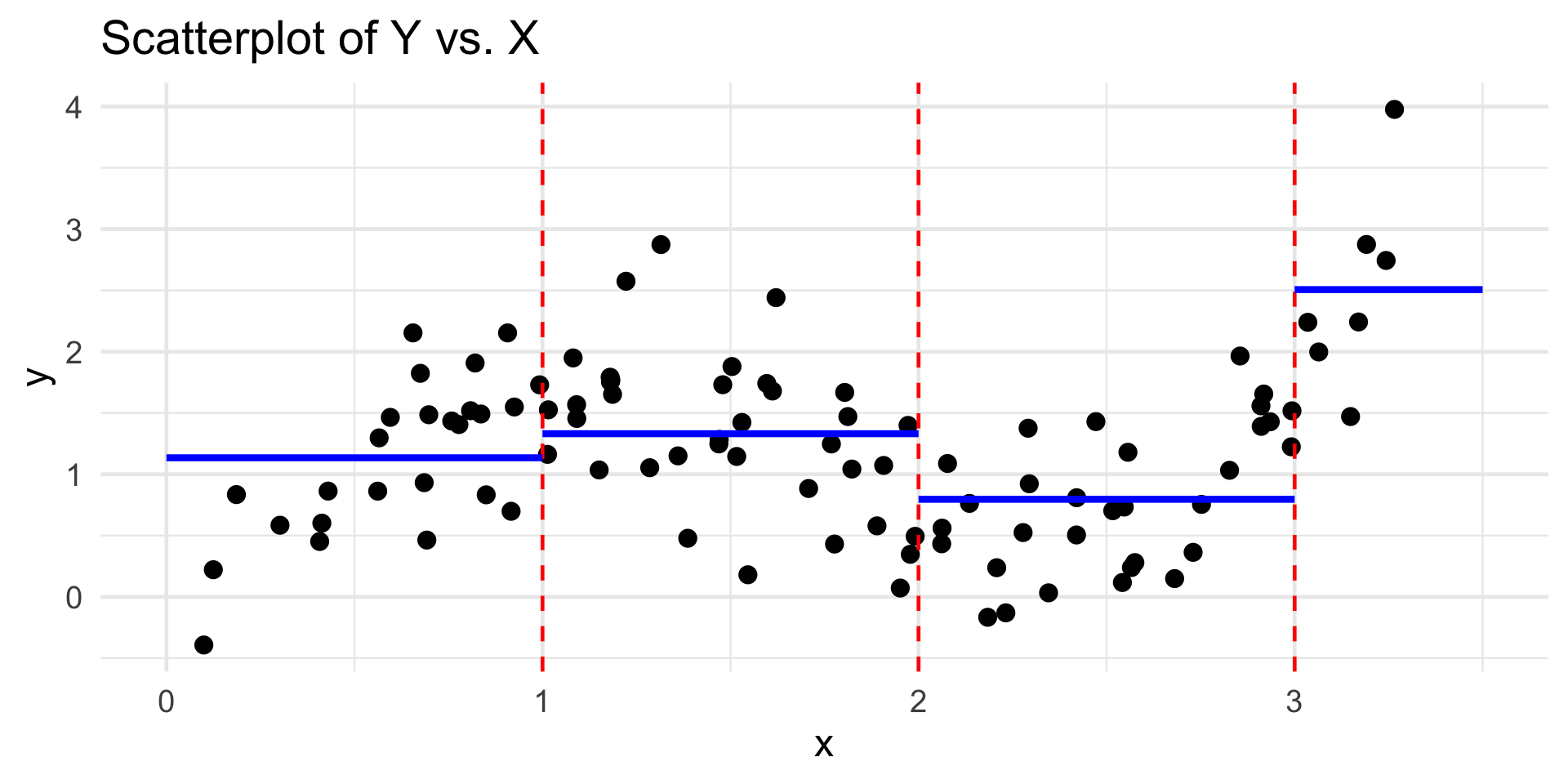
Piecewise Regression
Piecewise-Constant Regression
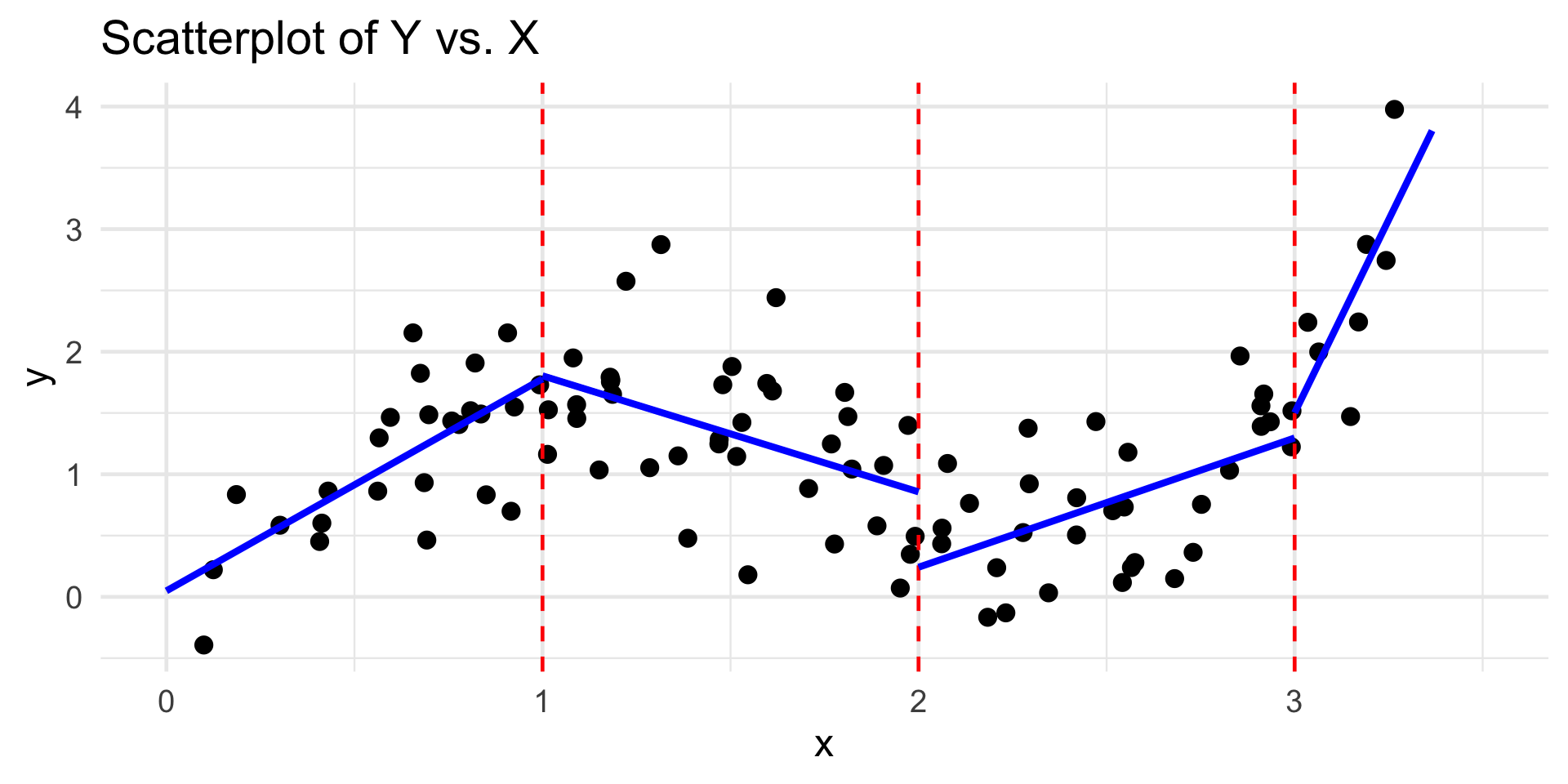
Piecewise Regression
Piecewise-Linear Regression
Piecewise Regression
Piecewise-Cubic Regression
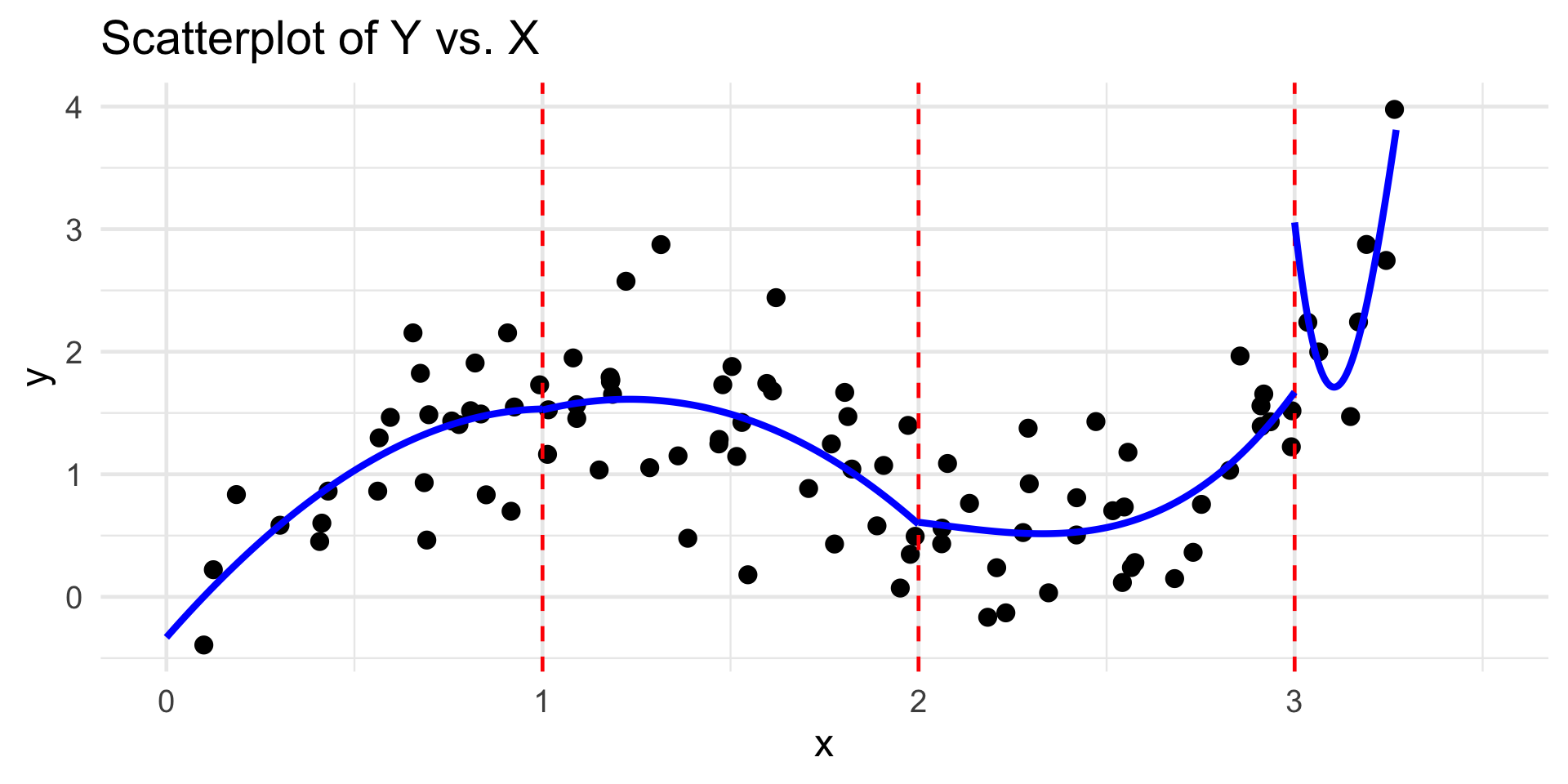
Piecewise Regression
Piecewise-Cubic Regression with Boundary Conditions
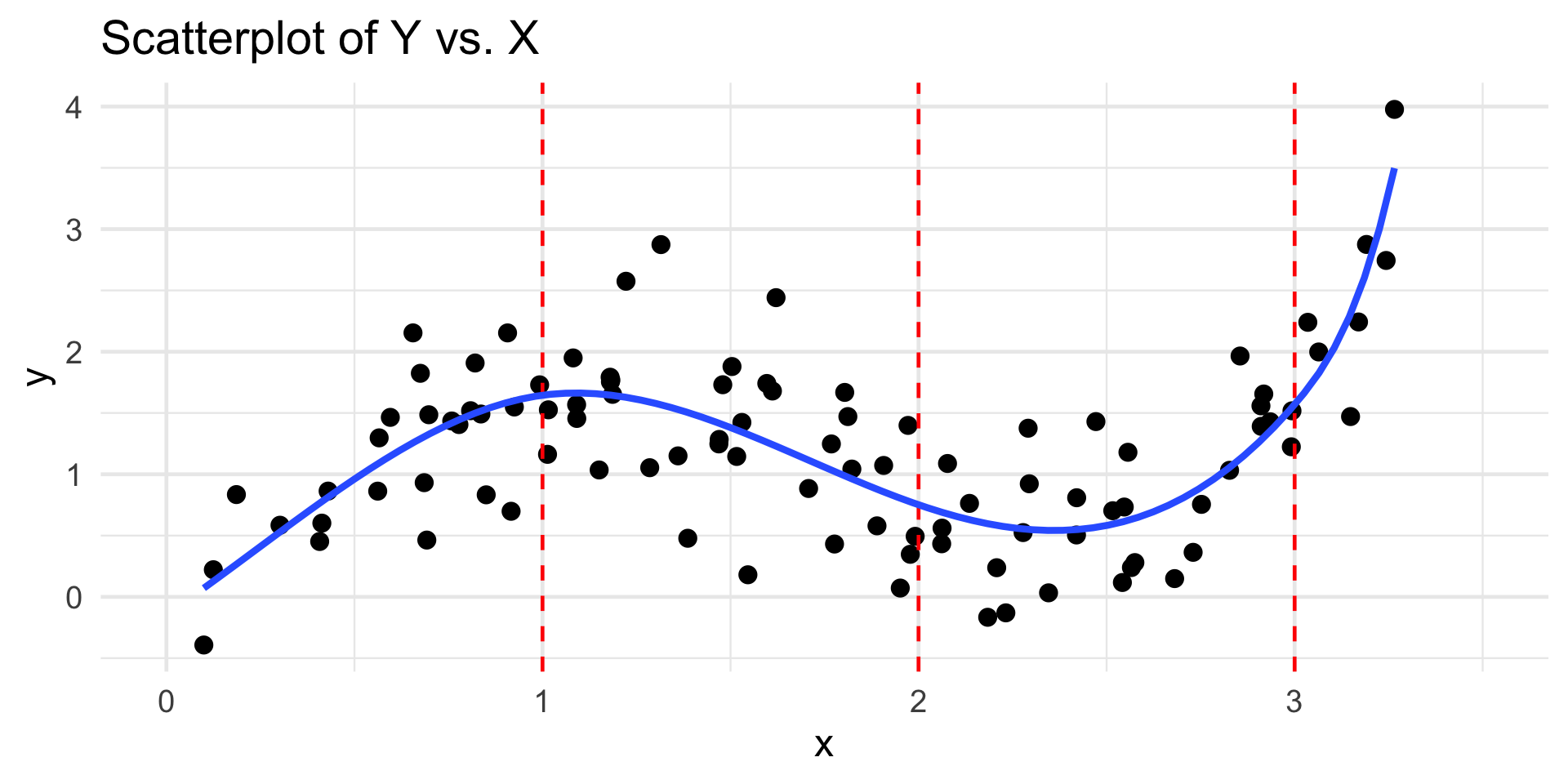
Series Estimators
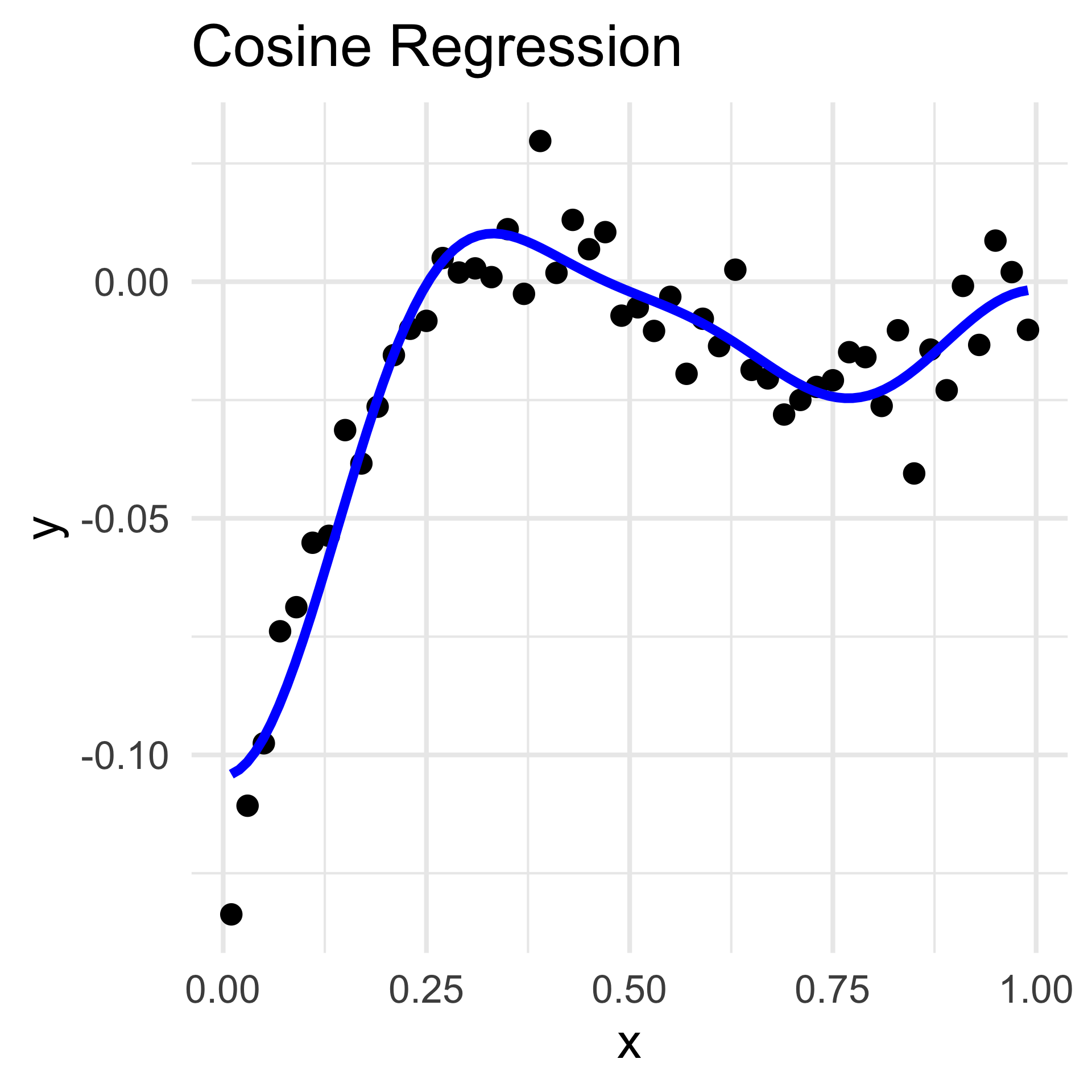
Trigonometric Regression
- Assuming equally-spaced inputs, we can also propose a class of trigonometric series estimators; for example,
\[ f(x) = \sum_{j=1}^{p} \beta_j \cos[(j - 1) \pi x]\]
- Selection of p can be accomplished with Cross-Validation (out-of-scope for PSTAT 100)