PSTAT 100: Lecture 14
Simple Linear Regression
Penguins
An Example

The
penguinsdataset, from thepalmerpenguinspackage, contains information on 344 penguins, collected by Dr. Kristen Gorman, at the Palmer Research Station in Antarctica.Three species of penguins were observed: Adélie, Chinstrap, and Gentoo
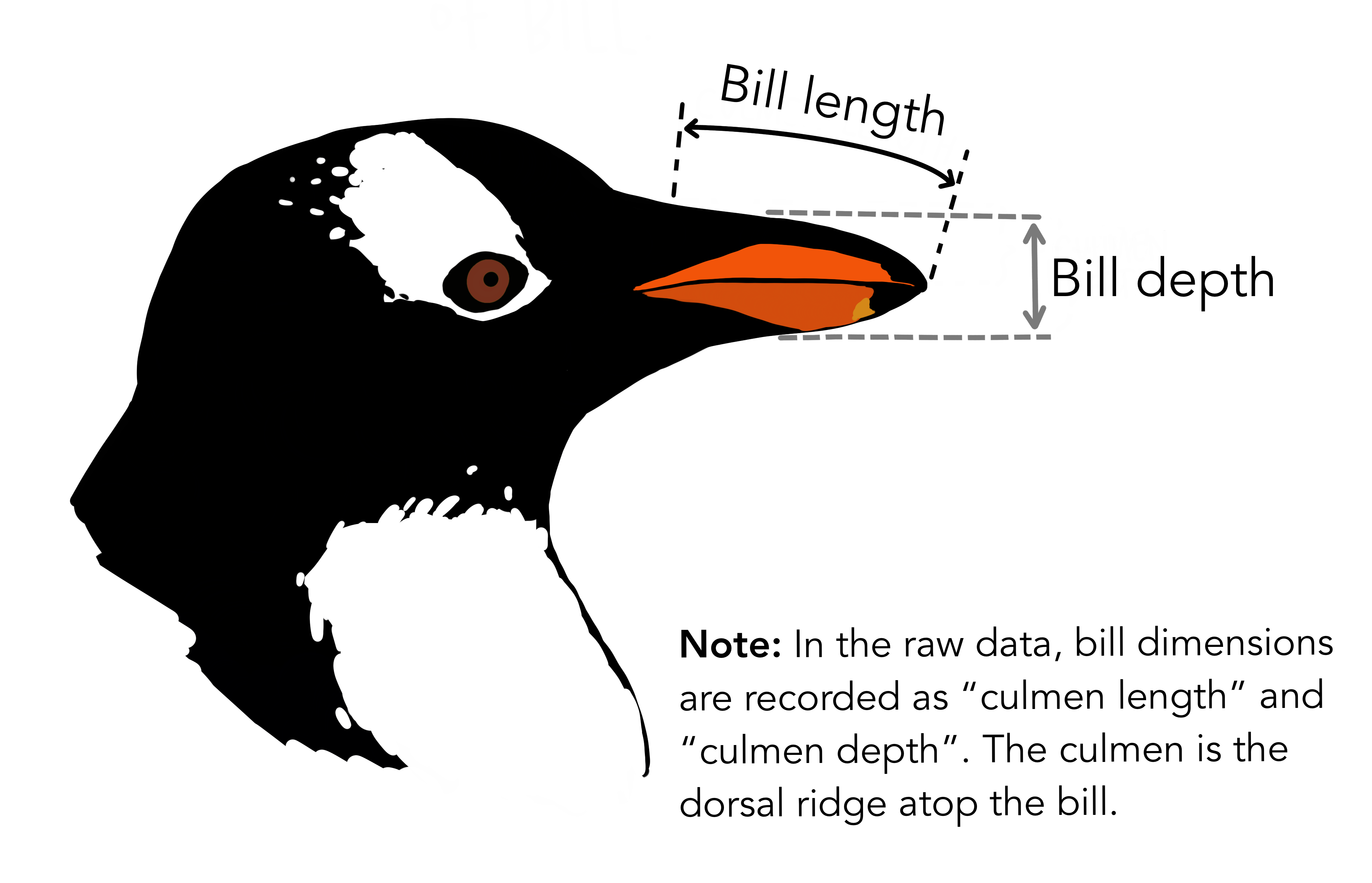
Various characteristics of each penguin were also observed, including: flipper length, bill length, bill depth, sex, and island.
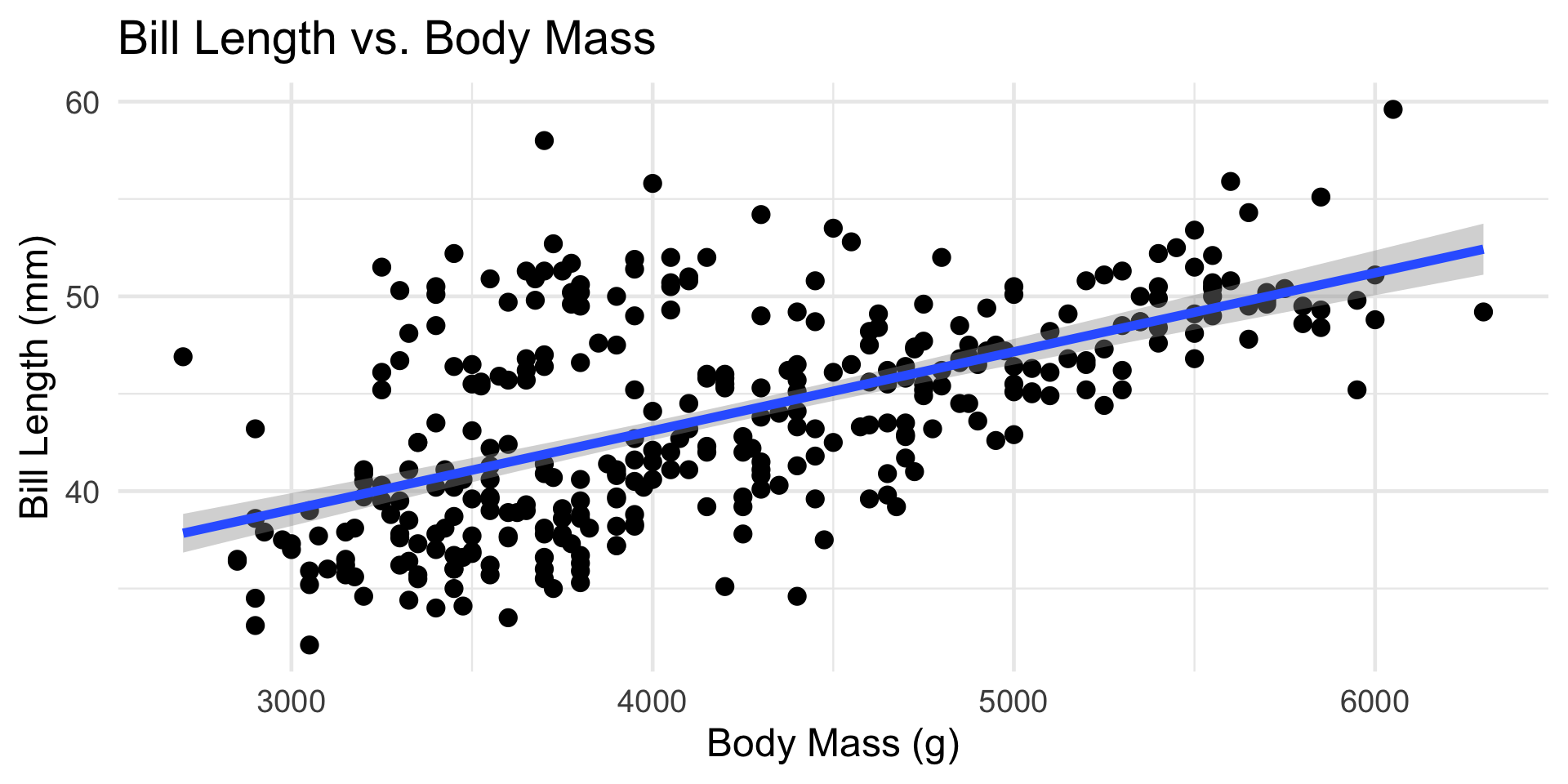
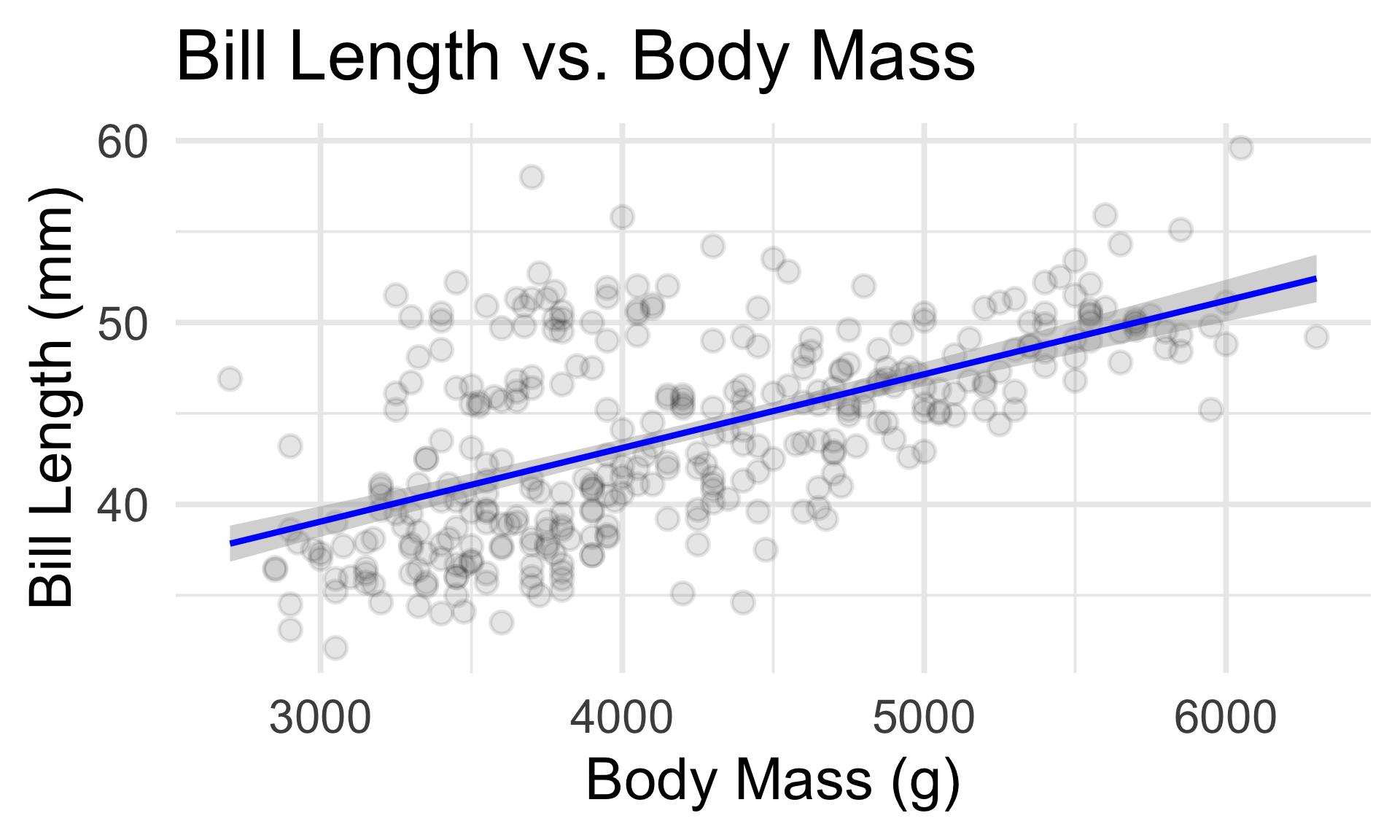
It seems plausible that a penguin’s bill length should be related to its body mass.
Penguins
An Example
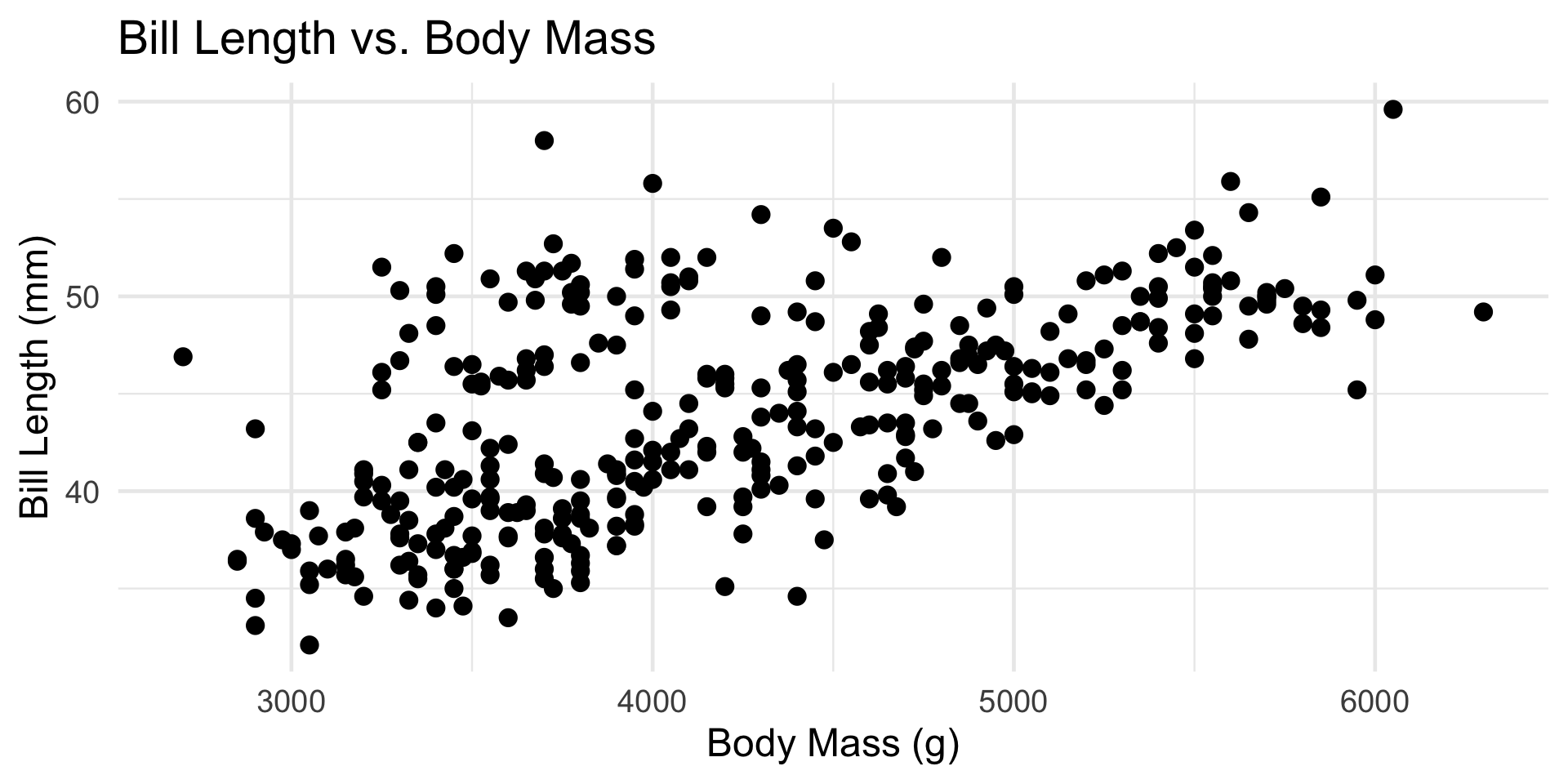
- Based on our discussions from Week 1:
- Is there a trend?
- Increasing or decreasing?
- Linear or nonlinear?
- If we model Bill Length (response) as a function of Body Mass (predictor), would this be a regression or a classification model?
Simple Linear Regression Model
As Applied to the Palmerpenguins Dataset
- Essentially, the SLR seeks to fit the “best” line to the data.
- The parameters that need to be estimated in the model fitting step are, therefore, the intercept and the slope.
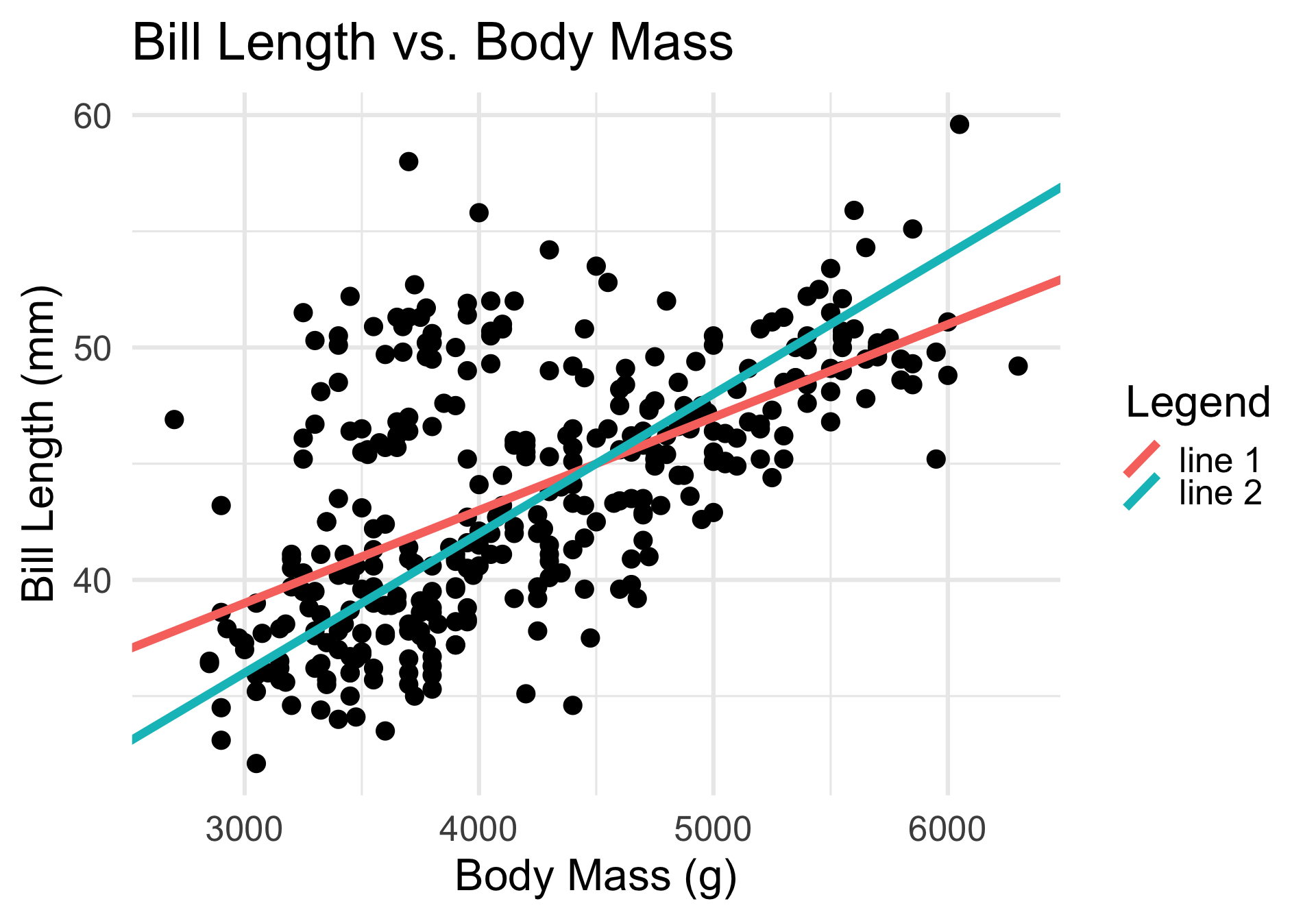
- Identifying these slope and intercept values by eye is next to impossible - this is why modeling is so useful!
Penguins
The Fitted SLR Model
Model Diagnostics
Example: Poor Choice of Model
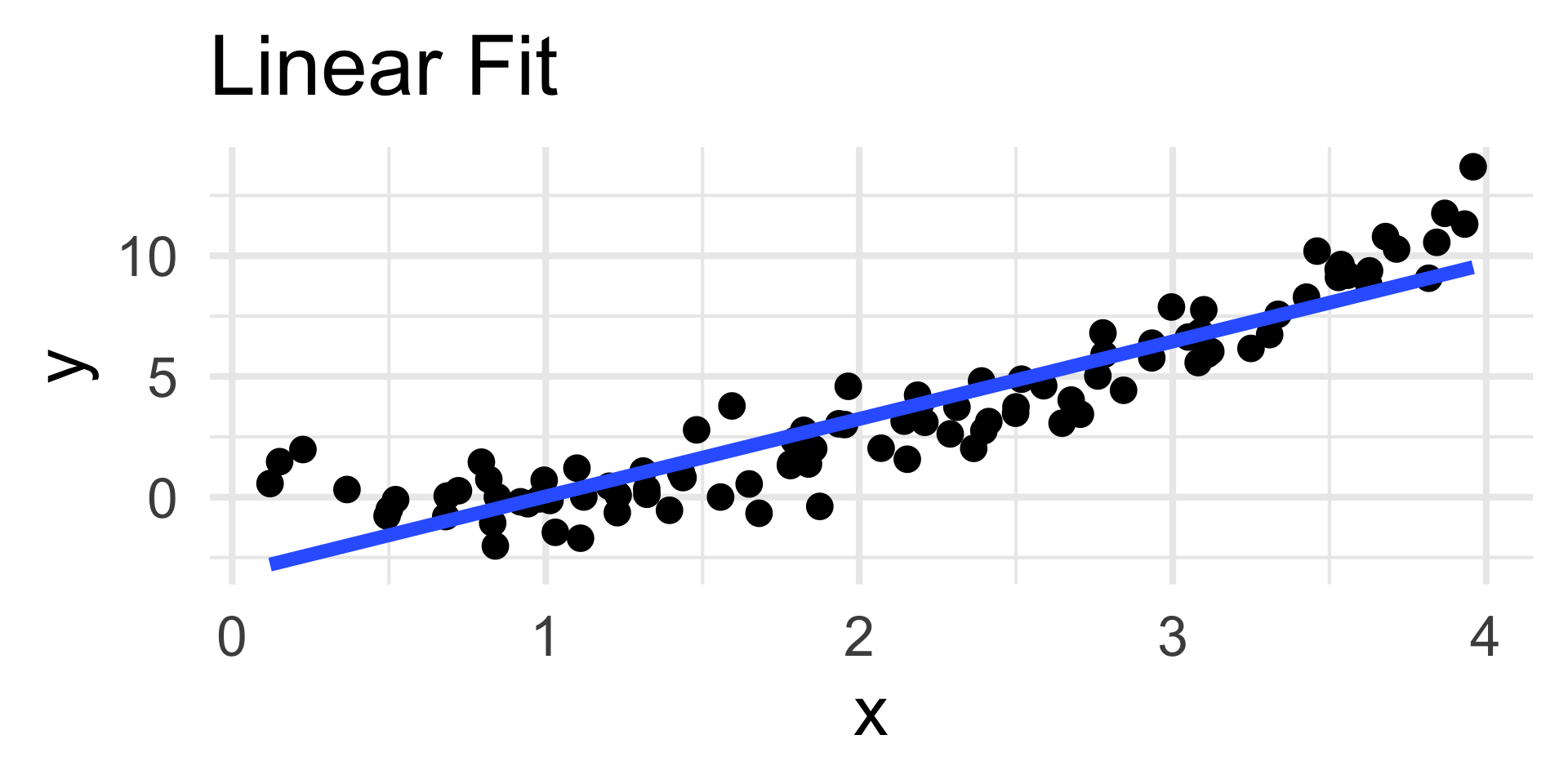
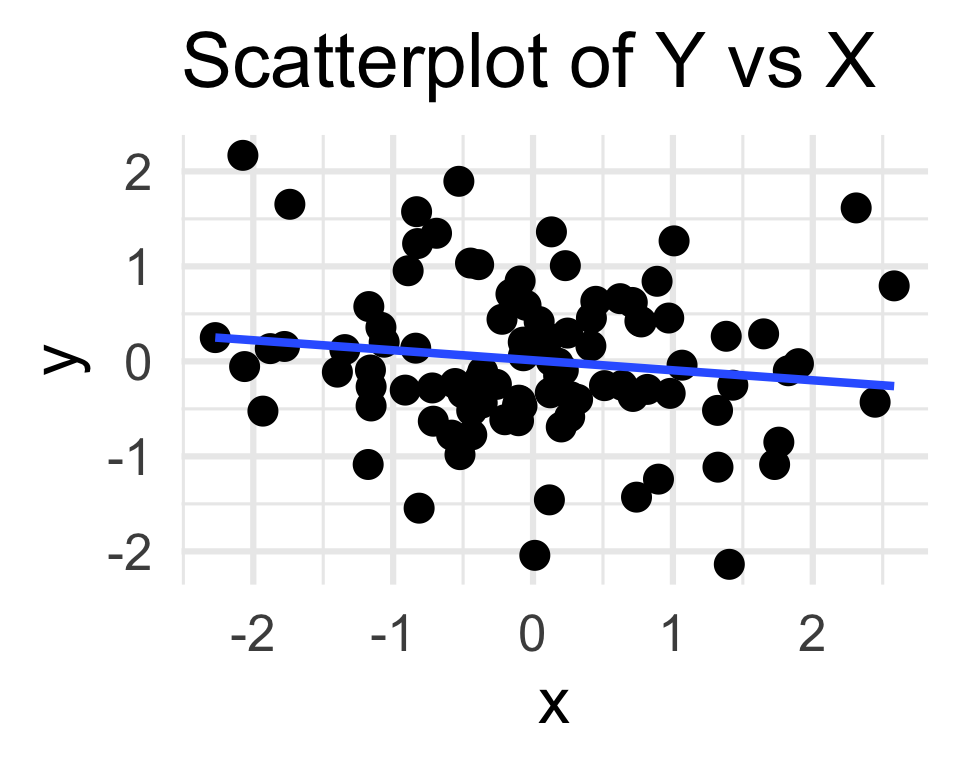
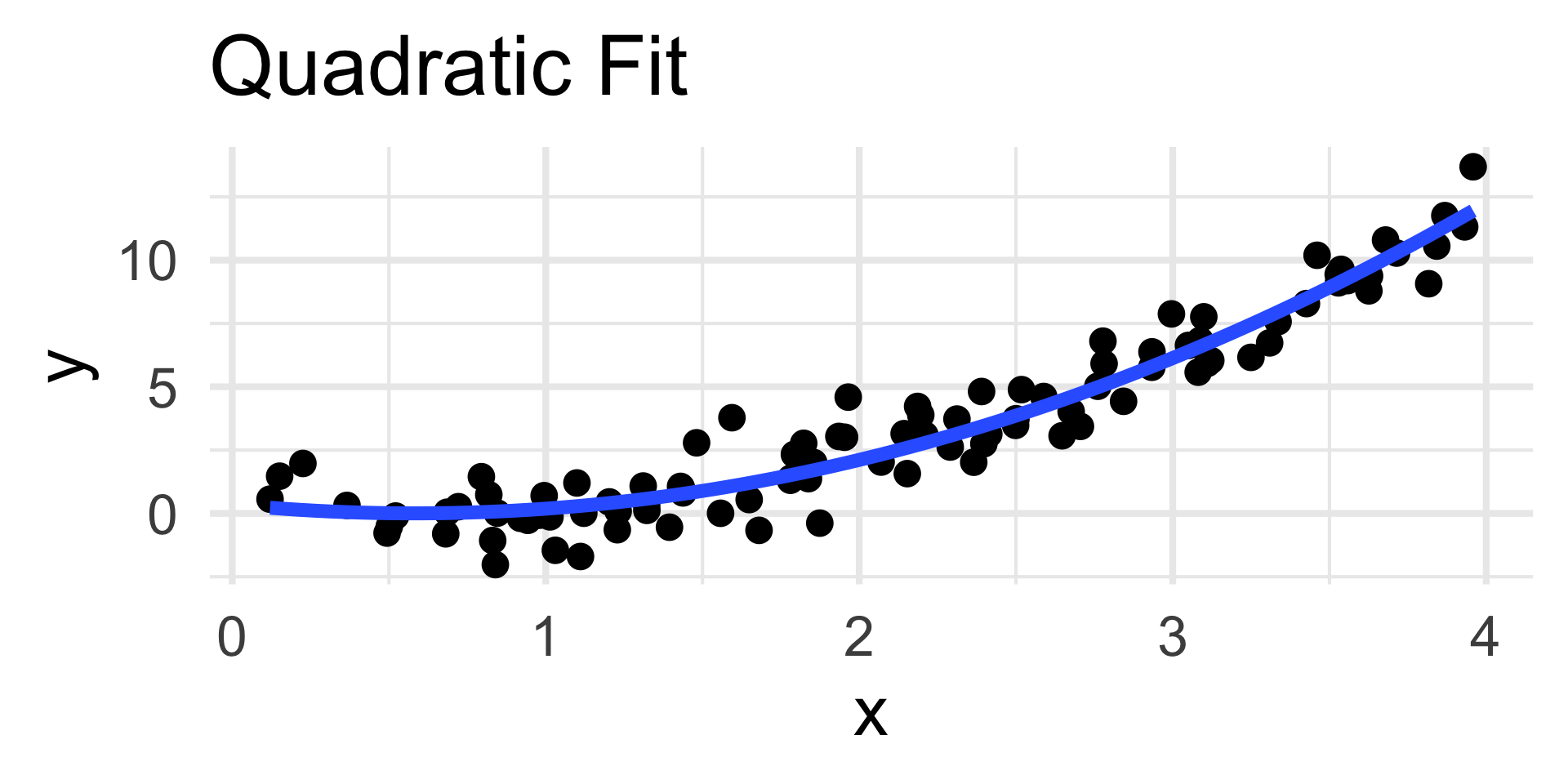
- For example, consider the simulated data to the left.
- The true relationship appears highly nonlinear; nevertheless, we have fit a linear model to the data.
- The coefficients of the linear fit are “optimal” - they minimize risk under squared-error loss!
- In other words, the blue line is the line of best fit to the data.
- But, visually, we believe that this line is not doing a good job of capturing the overall trend in the data.
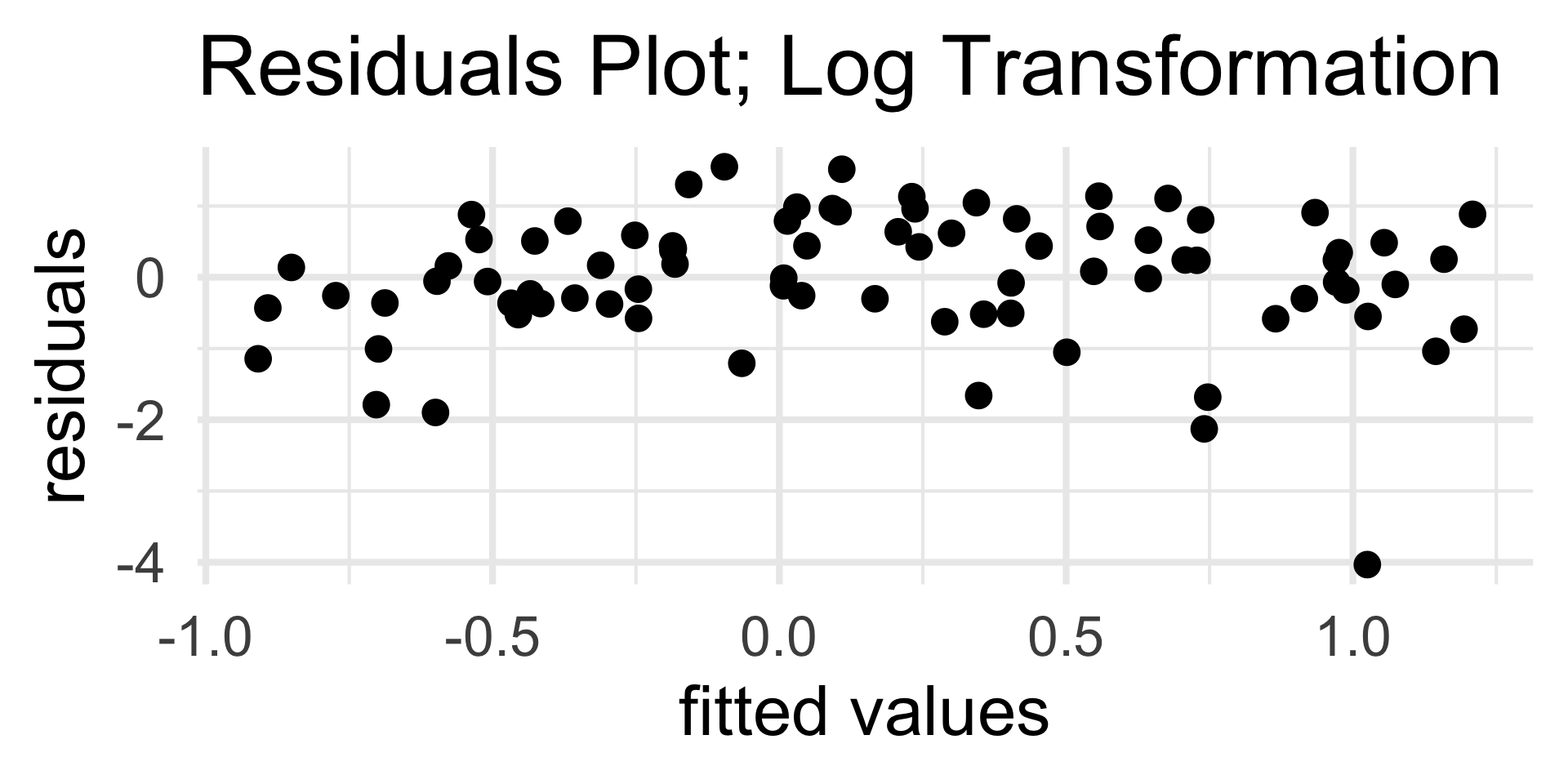
Residuals Plots
Examples
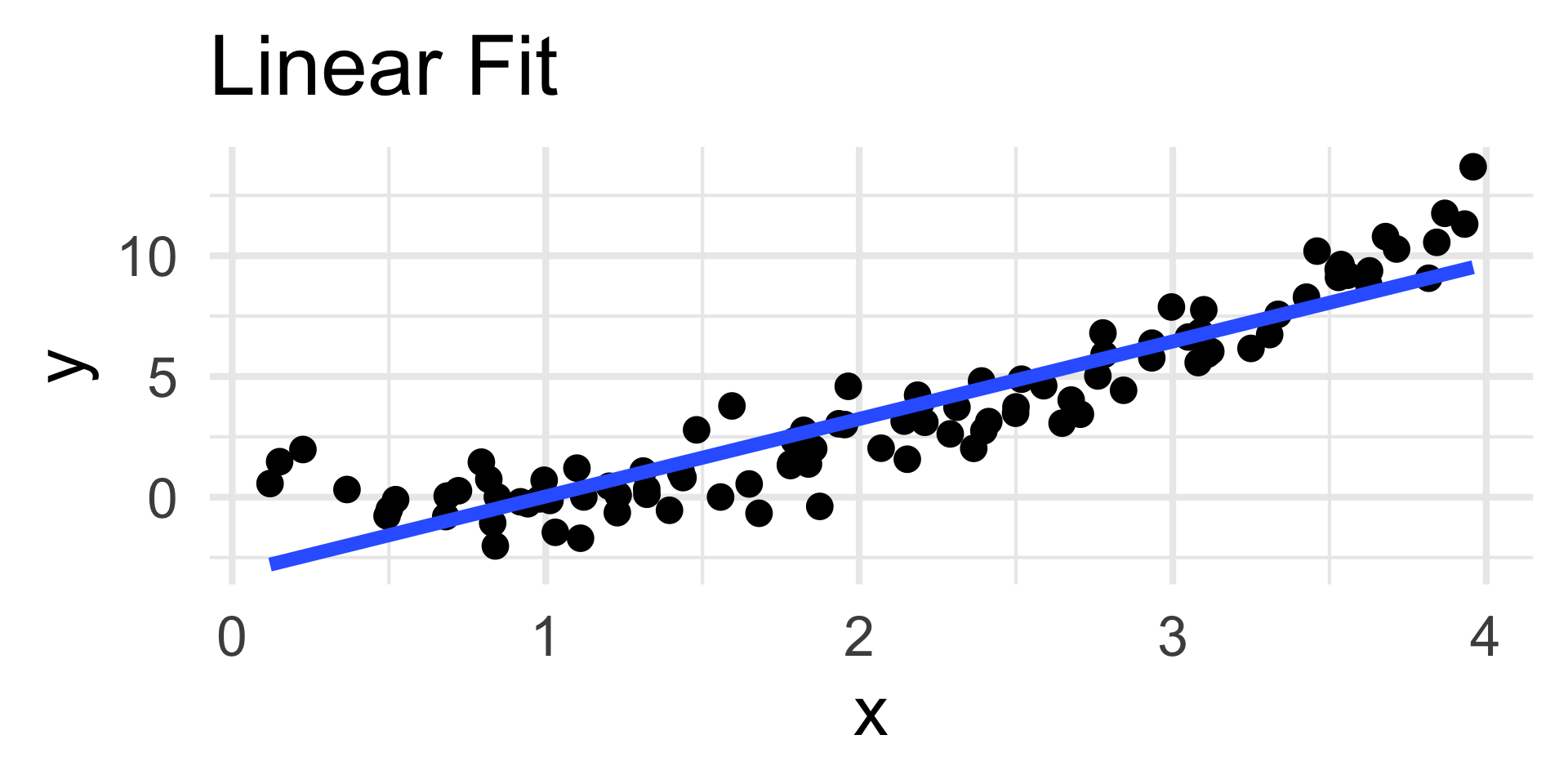
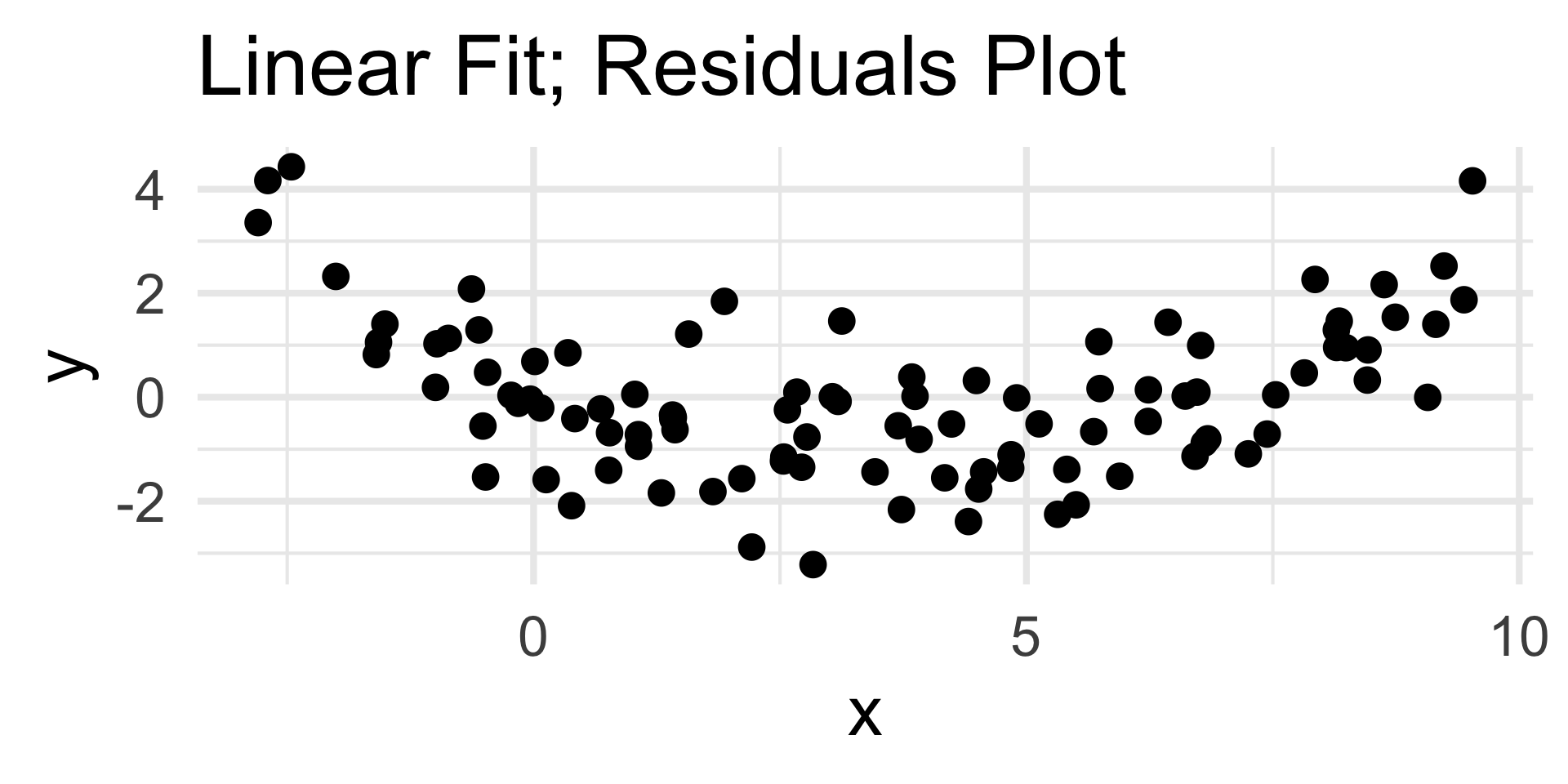
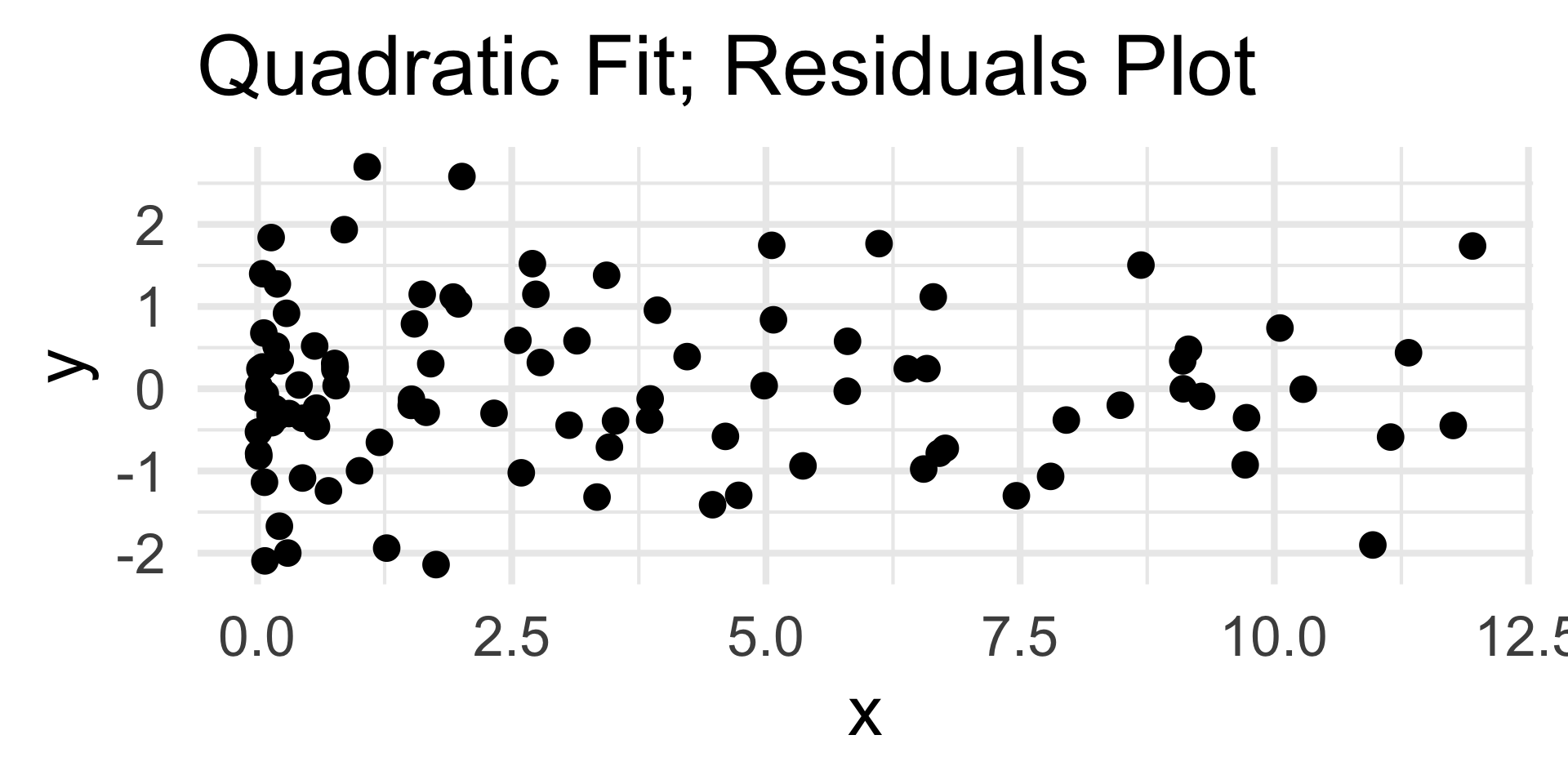
- The residuals plot displays a clear quadratic trend, indicating a poor choice of model.
- The scatterplot on the left confirms this.
- Note that the nature of the trend in the residuals plot is indicative of the portion of the model missing; we’ll return to this in a bit.
Residuals Plots
Examples
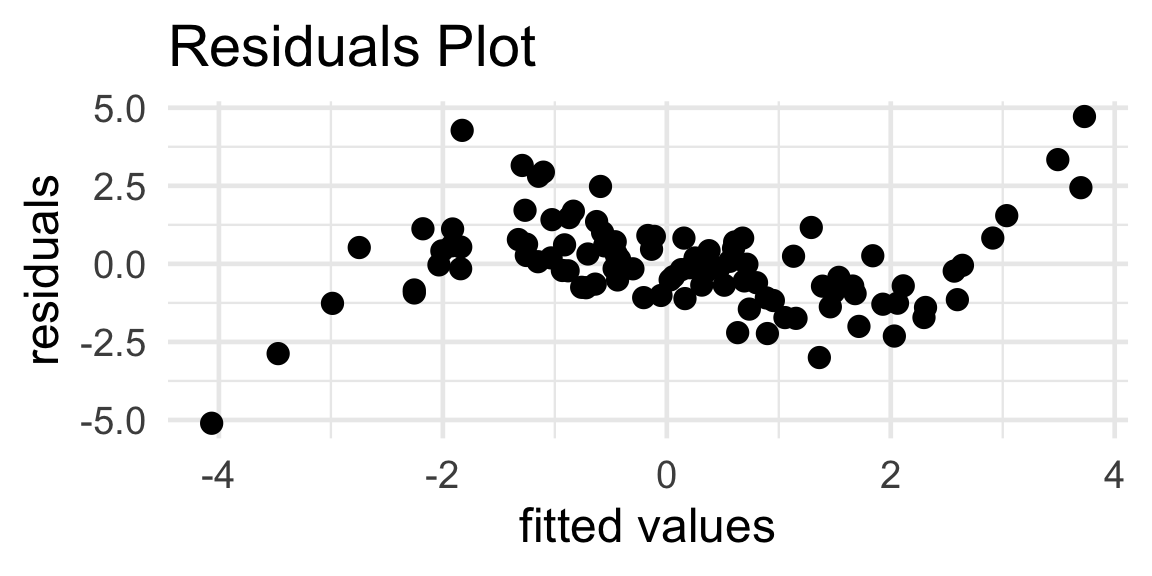
- Now, the residuals plot displays no discernable trend along with homoskedasticity.
- This indicates that our choice of quadratic fit was good; certainly in comparison to the linear fit.
Misspecified Model
Trend in Residuals
Moral
If the residuals plot displays a trend of the form g(ŷ) for some function g, consider incorporating a term of the form g(x) into the original model.
Your Turn!
When a simple linear regression model is fit to a particular dataset, the resulting residuals plot is:
Propose an improved model, and justify your choice of improvement.
03:00
Diagnostic 2
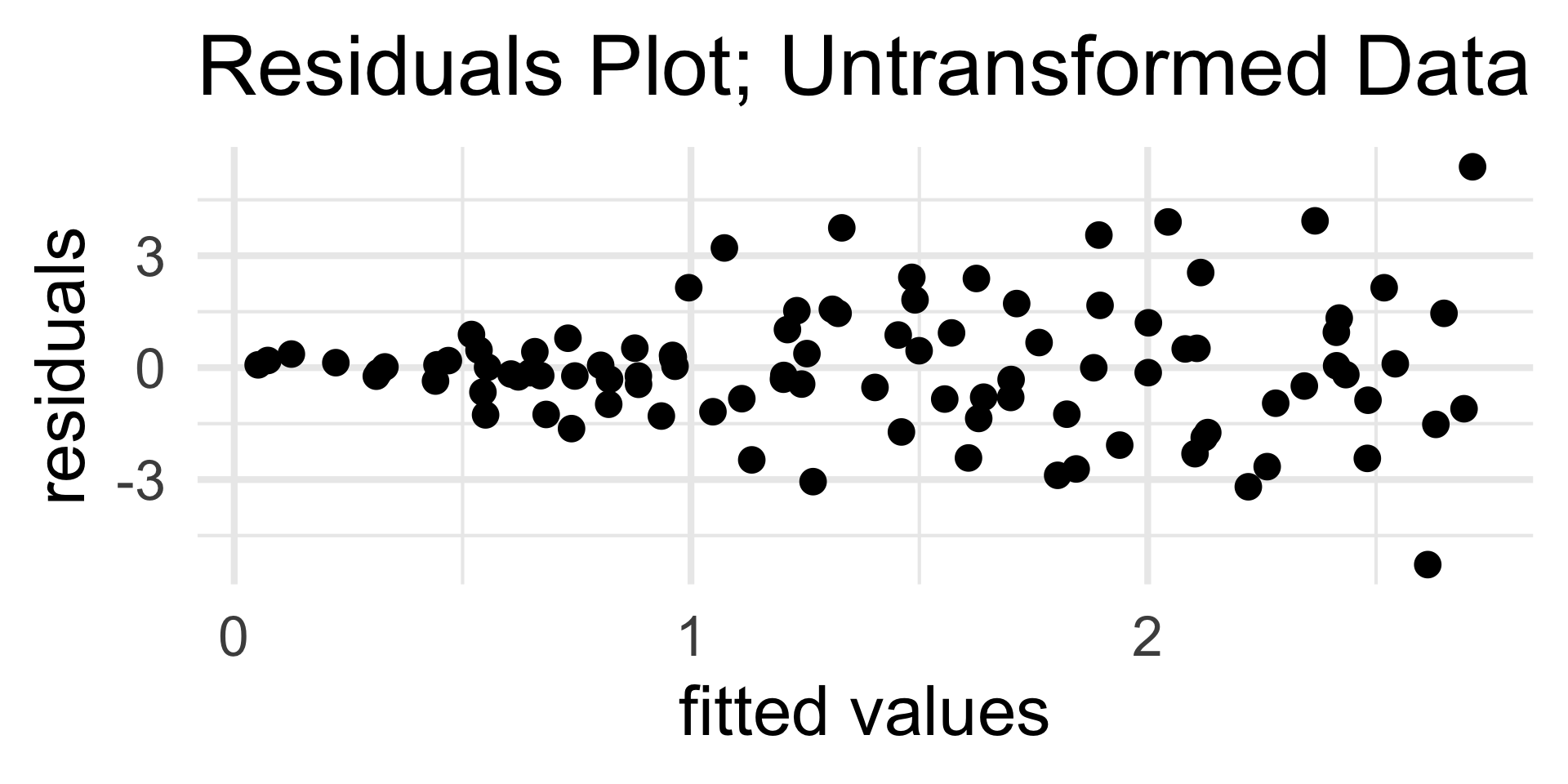
Heteroskedasticity in Residuals
The other type of “problem” we might encounter in a residuals graph is heteroksedasticity (i.e. nonconstant variance).
There are a couple of different ways to address heteroskedasticity, most of which I’ll leave for your future PSTAT courses to discuss.
- For the purposes of PSTAT 100, you should just be able to identify the presence of heteroskedasticity from a residuals plot
Why Model?
Prediction
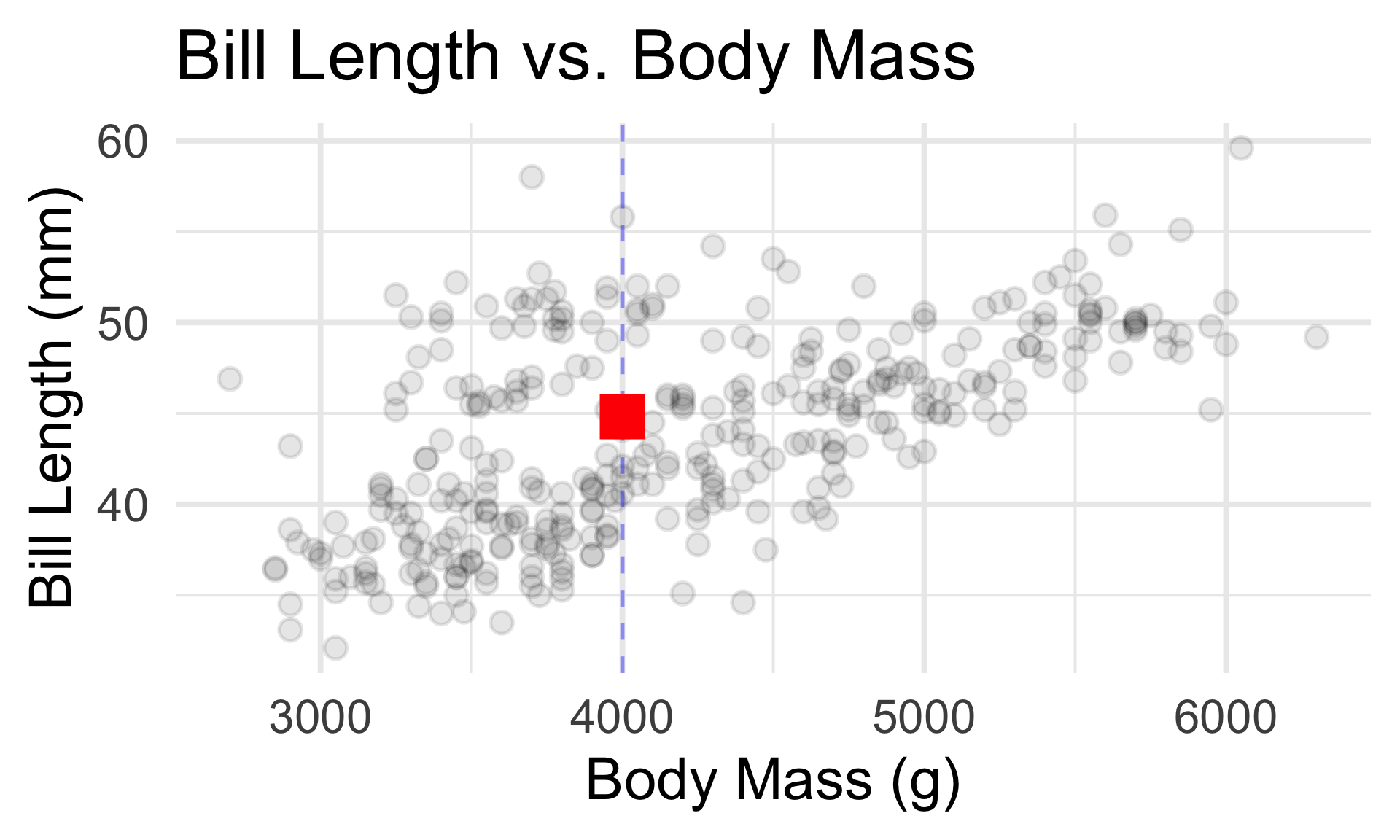
- What’s the true (de-noised) bill length (in mm) of a 4000g penguin?
Inference
- How confident are we in our guess about the relationship between bill length and body mass?
Prediction: Example
gentoo <- penguins %>% filter(species == "Gentoo")
lm1 <- lm(bill_depth_mm ~ body_mass_g, gentoo)
(y1 <- predict(lm1, newdata = data.frame(body_mass_g = 5010))) 1
14.88971 Code
gentoo %>% ggplot(aes(x = body_mass_g,
y = bill_depth_mm)) +
geom_point(size = 4, alpha = 0.4) +
theme_minimal(base_size = 24) +
annotate("point", shape = 15, x = 5010, y = y1, col = "red", size = 6) +
xlab("body mass (g)") + ylab("bill depth (mm)") +
ggtitle("Bill Depth vs. Body Mass",
subtitle = "Gentoo Only")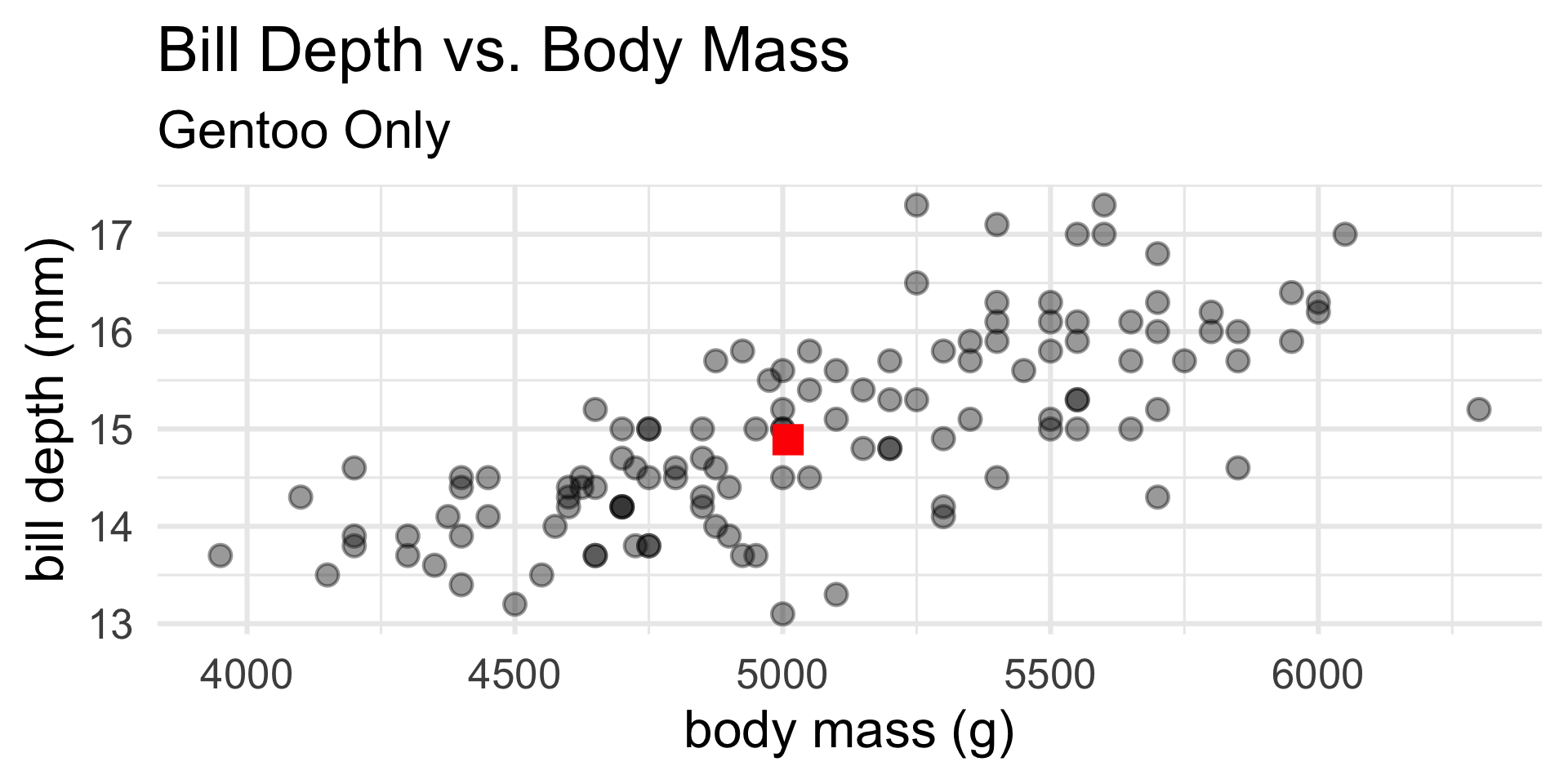
Prediction: Example
- For a general statistical model
yi=f(xi) + εi , a prediction for the true response value at an inputxis given by first estimatingf(either parametrically or nonparametrically) by \(\widehat{f}\), and then returning a fitted value \[ \widehat{y}_i := \widehat{f}(x) \]

Dangers of Extrapolation
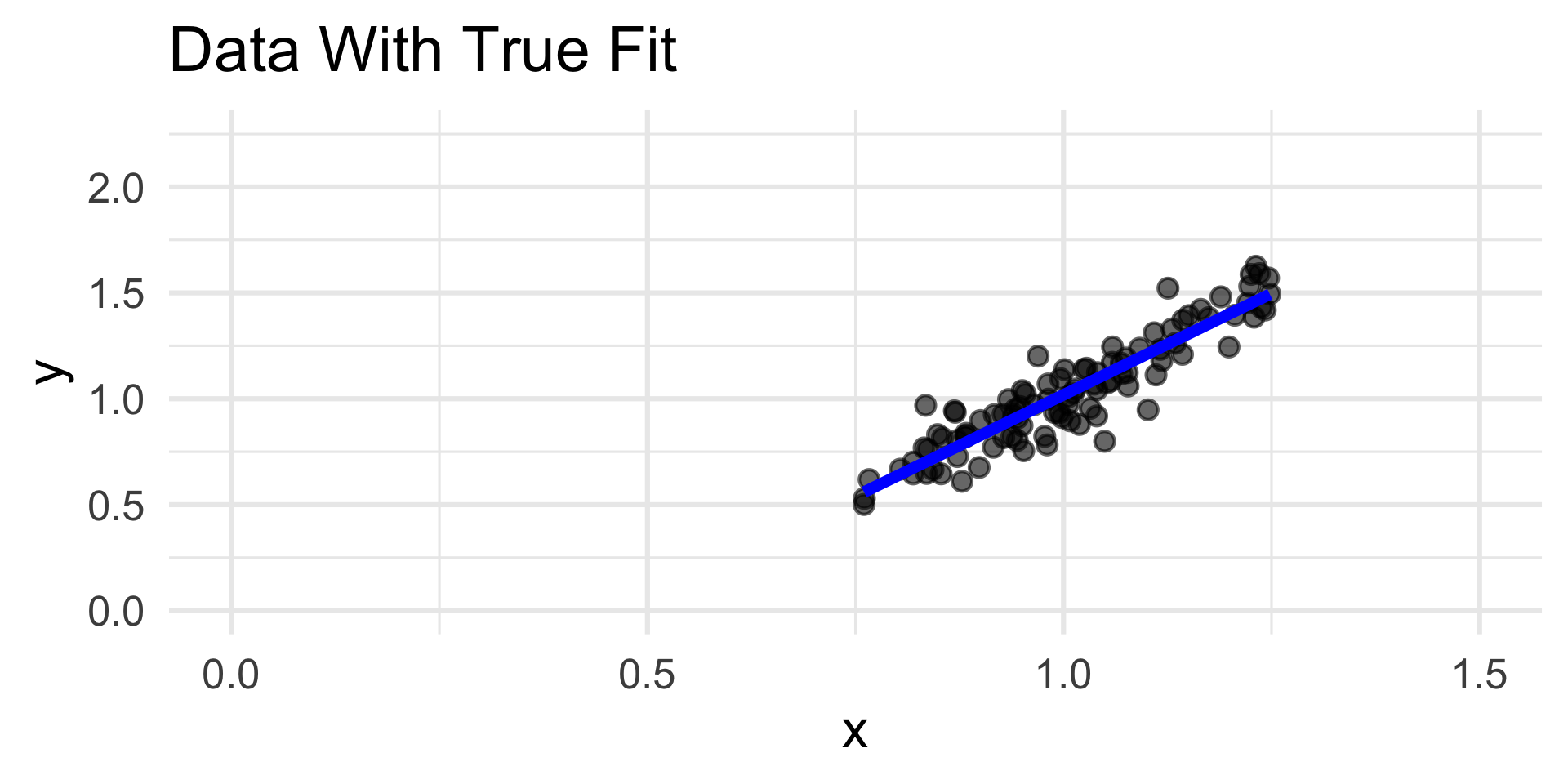
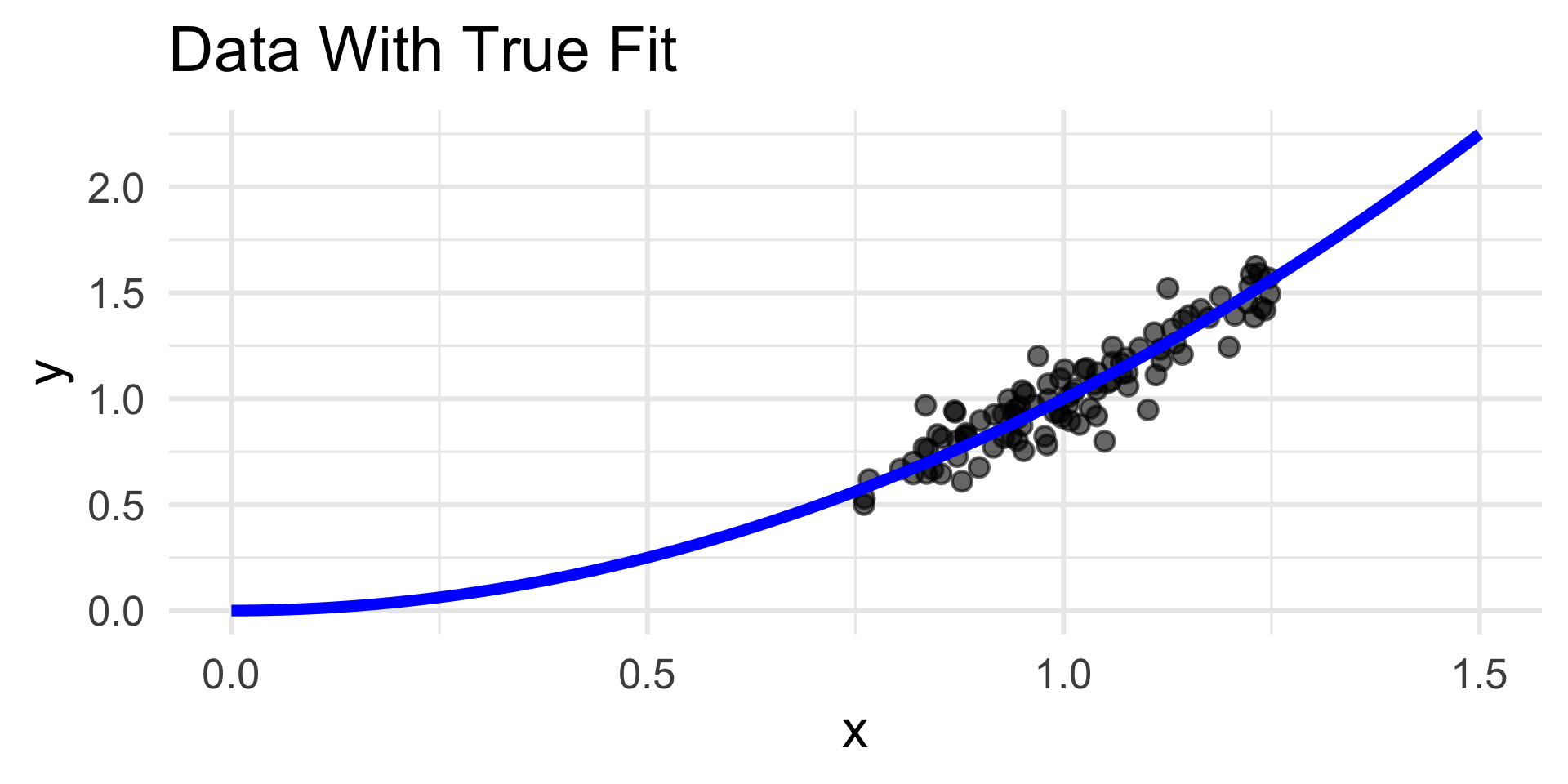
- Our “optimal” model fit is only optimal for the range of data on which it was fit.
- Extrapolation (predicting based on predictor values far outside the range originally observed) assumes that our proposed model holds even far outside the range of data we initially observed - an assumption that is very dangerous to make.
- So, don’t do it!
Inference
Regression Tables
- We saw something like
Pr(>|t|)in Lab yesterday. What context was that in, and what did this quantity mean in that context?