PSTAT 100: Lecture 10
Estimation, Confidence Intervals, and Resampling
Recap: Statistical Inference
- Yesterday we talked about the general framework of statistical inference.
We have a population, governed by a set of population parameters that are unobserved (but that we’d like to make claims about).
To make claims about the population parameters, we take a sample.
We then use our sample to make inferences (i.e. claims) about the population parameters.

Recap: Statistical Inference

- A function of the random sample is an estimator
- This is a random quantity; “if I were to take a sample, …”
- The corresponding function of the observed instance (aka realization) of the sample is called an estimate
- This is a deterministic quantity; “given this particular sample I took, …”
Sampling Distributions
Sample Mean: Non-Normal Population; Unknown Variance

Sampling Distributions
Sample Mean: Non-Normal Population; Unknown Variance

Sampling Distributions
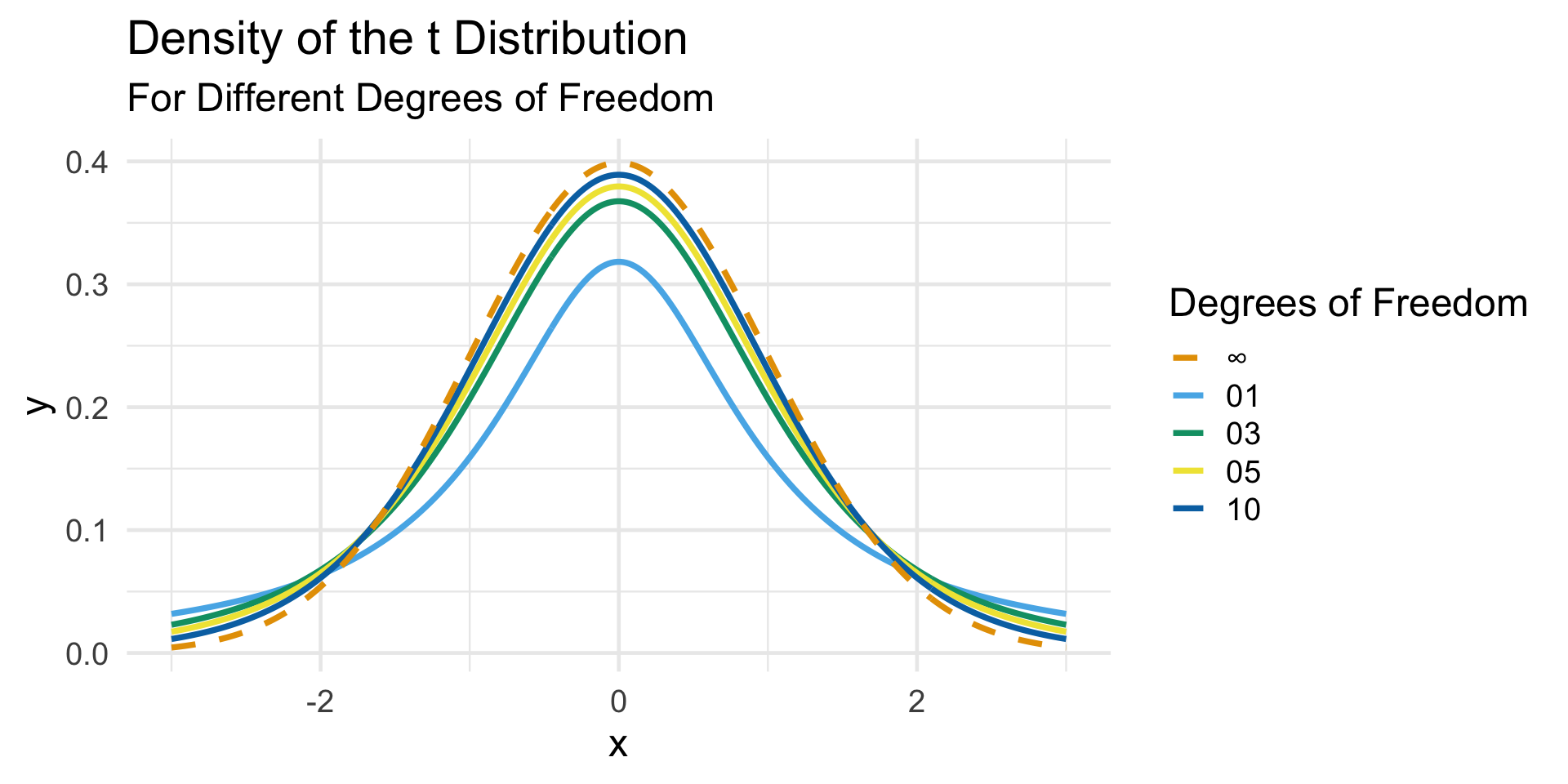
The t Distribution
Sampling Distributions
Sample Mean: Non-Normal Population; Unknown Variance

Bootstrapping: Example
- If we imagine repeating this resampling procedure, we can construct an approximation to the sampling distribution of the sample mean.
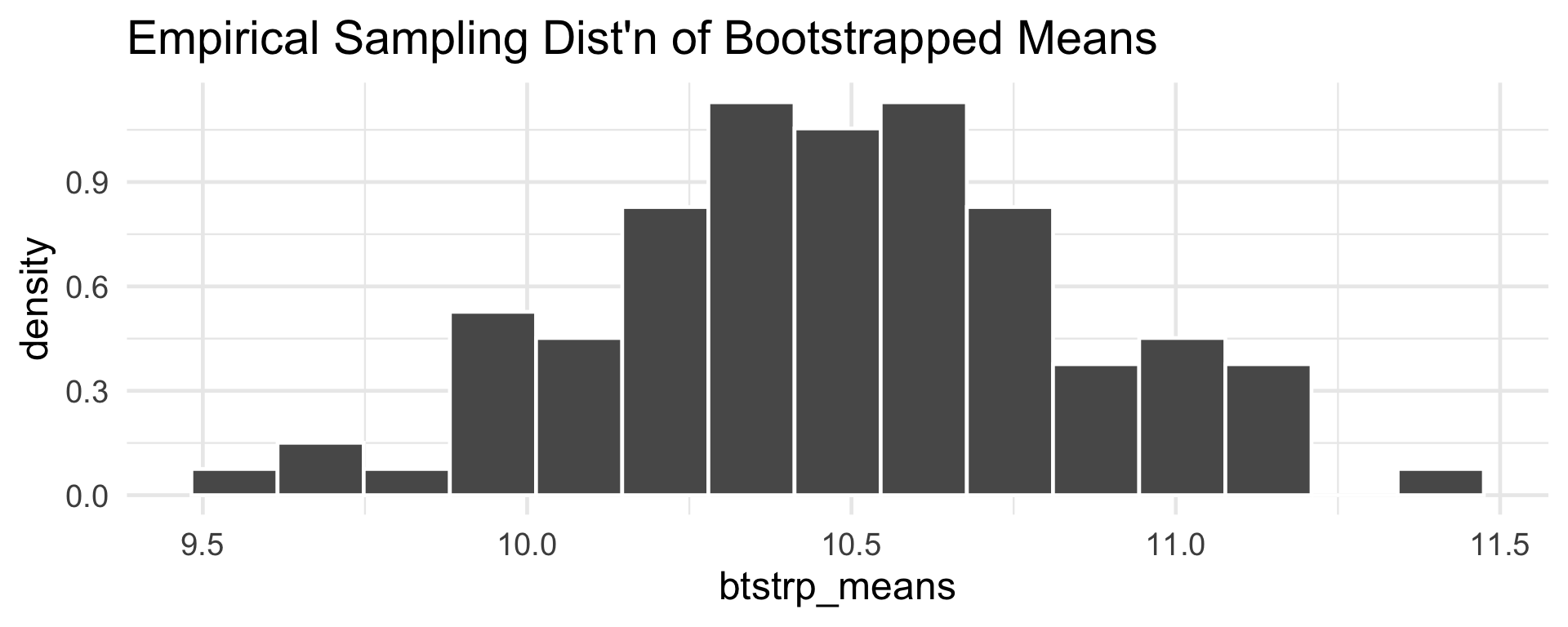
Bootstrapping: Example
Code
data.frame(`From Pop.` = sm_from_pop,
`Bootstrapped` = btstrp_means,
check.names = F) %>%
melt(variable.name = "type") %>%
ggplot(aes(x = type, y = value)) +
geom_boxplot(fill = "#dce7f7", staplewidth = 0.25,
outlier.size = 2) + theme_minimal(base_size = 18) +
ggtitle("Boxplot of Means",
subtitle = "Sampled from Population, and Bootstrapping")
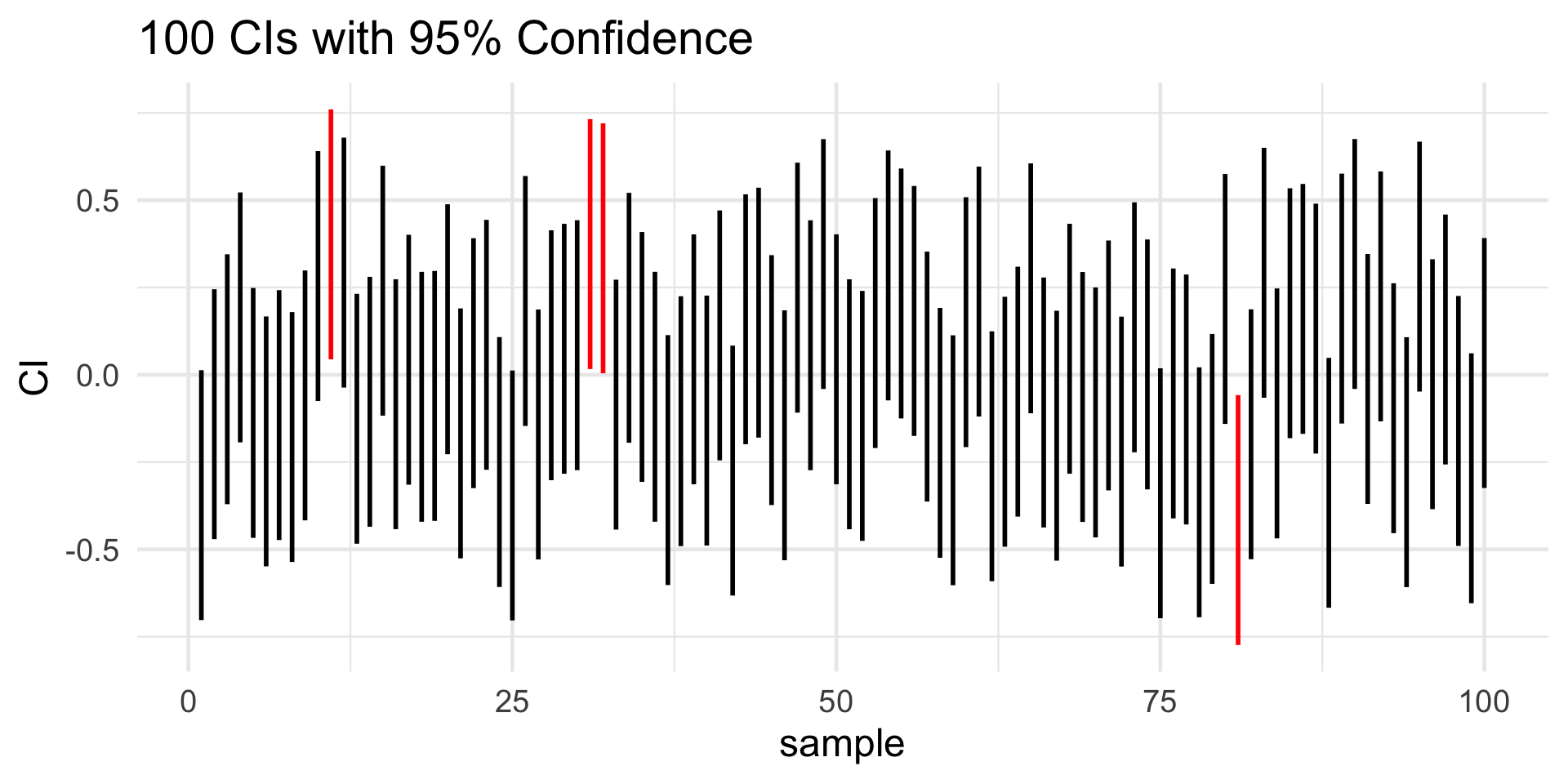
CI: Interpretation